Sep 5, 2018
TechnologySteps
最先是在VPS上用docker开发,遇到跨域问题,专用虚拟机开发。
# vagrant init bento/ubuntu-18.04
更改IP为192.168.33.128/24, 2 Core/ 2G
# vagrant up
# vagrant ssh
安装必要的开发环境。
# sudo apt-get install -y npm nodejs
# npm install -g express
# npm install -g express-generator
# which express
/usr/local/bin/express
创建一个名称为countdown的express项目:
# express -v ejs countdown
# cd countdown/
# ls
app.js bin package.json public routes views
安装依赖:
# npm install -d
# npm install socket.io express --save
此时可以查看package.json的内容:
{
"name": "countdown",
"version": "0.0.0",
"private": true,
"scripts": {
"start": "node ./bin/www"
},
"dependencies": {
"cookie-parser": "~1.4.3",
"debug": "~2.6.9",
"ejs": "~2.5.7",
"express": "^4.16.3",
"http-errors": "~1.6.2",
"morgan": "~1.9.0",
"socket.io": "^2.1.1"
}
}
我们需要使用layout(比较陈旧的用法),因而执行以下操作:
# npm install ejs-locals --save
代码更改
在// view engine setup前添加以下代码,作用是用于指定当前app的服务端口,并定义socket.io的模块引入:
var engine = require('ejs-locals');
var server = require('http').createServer(app);
var io = require('socket.io')(server);
//(server,{
// transports : [ 'xhr-polling' ]
//});
server.listen(5000);
// Todo: xhr-polling的意义?
在view engine setup中添加ejs-local的用法,
我们这里将指定layout.ejs为我们模板中的布局文件:
// view engine setup
app.set('views', path.join(__dirname, 'views'));
app.set('view options', { layout:'views/layout.ejs' });
app.engine('ejs', engine);
app.set('view engine', 'ejs');
接着我们引入状态变量及对io的用法:
// status indicator
var status = "All is well.";
io.sockets.on('connection', function (socket) {
io.sockets.emit('status', { status: status }); // note the use of io.socket
s to emit but socket.on to listen
socket.on('reset', function (data) {
status = "War is imminent!";
io.sockets.emit('status', { status: status });
});
});
module.exports = app;
模板文件定义:
# cat views/layout.ejs
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Title</title>
<meta name="description" content="">
<meta name="author" content="">
<!-- HTML5 shim, for IE6-8 support of HTML elements -->
<!--[if lt IE 9]>
<script src="http://html5shim.googlecode.com/svn/trunk/html5.js"></script>
<![endif]-->
<!-- styles -->
<link href="/stylesheets/main.css" rel="stylesheet">
</head>
<body>
<%- body %>
<script src="/socket.io/socket.io.js"></script>
<script src="/javascripts/libs/jquery.js"></script>
<script src="/javascripts/main.js"></script>
</body>
</html>
以及index.ejs:
# cat views/index.ejs
<% layout('layout') -%>
<div id="status"></div>
<button id="reset">Reset!</button>
main.js的定义文件如下:
# vim public/javascripts/main.js
var socket = io.connect(window.location.hostname);
socket.on('status', function (data) {
$('#status').html(data.status);
});
$('#reset').click(function() {
socket.emit('reset');
});
jquery.js文件如下:
# cd public/javascripts/
# mkdir libs && cd libs
# wget https://code.jquery.com/jquery-3.3.1.js
# mv jquery-3.3.1.js jquery.js
main.css文件同样也需要定义:
# vim public/stylesheets/main.css
内容略过
现在运行node app.js可以看到运行结果:
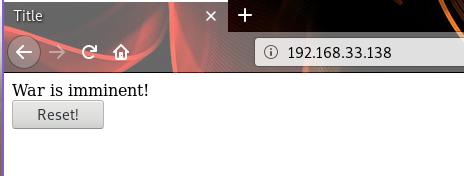
改进
timer的改进,具体的代码已经上传到github上。
Todo: 多个Timer的添加。
Todo: 跨域问题的解决。
Sep 4, 2018
TechnologyDiagram
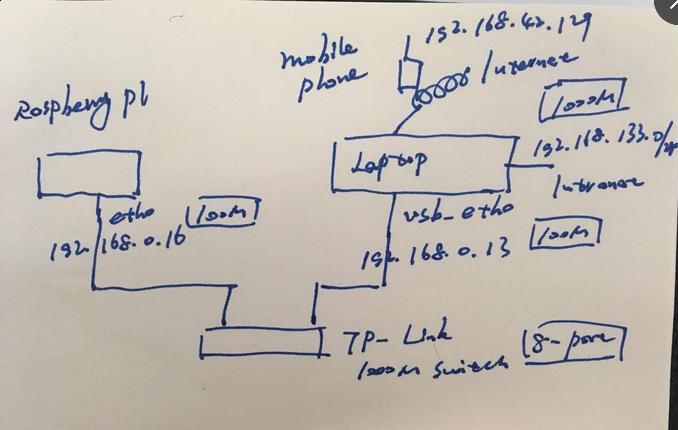
Command
RPI: 192.168.0.16/24
Laptop USB Ethernet Adapter: 192.168.0.33/24
Laptop:
# sudo iptables -t nat -A POSTROUTING -s 192.168.0.16/24 ! -d 192.168.0.16/24 -j MASQUERADE
Rpi:
# sudo route delete default gw 192.168.0.1
# sudo route add default gw 192.168.0.33
# sudo vim /etc/resolv.conf
nameserver 192.168.42.129
Thus your rpi could directly go to the internet.
Sep 4, 2018
Technology连线图:
RFID-RC522 board - Raspberry PI 1 Generation.
SDA connects to Pin 24.
SCK connects to Pin 23.
MOSI connects to Pin 19.
MISO connects to Pin 21.
GND connects to Pin 6.
RST connects to Pin 22.
3.3v connects to Pin 1.
OR:
(RC522) --- (GPIO RaspPi)
3.3v --- 1 (3V3)
SCK --- 23 (GPIO11)
MOSI --- 19 (GPIO10)
MISO --- 21 (GPIO09)
GND --- 25 (Ground)
RST --- 22 (GPIO25)
RPI 配置 SPI
打开配置窗口:
# sudo raspi-config
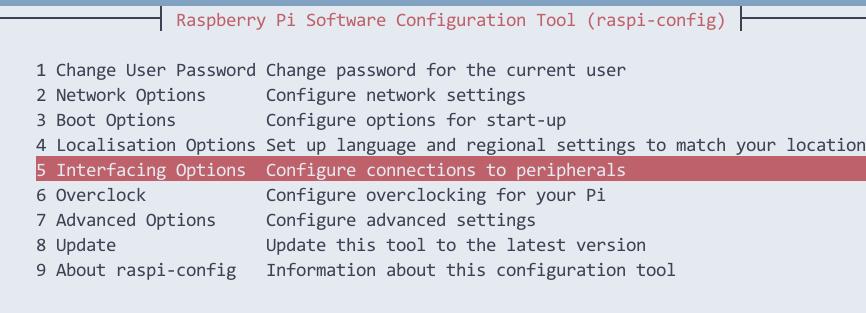
鼠标点击5 Interfacing Options, 选择P4 SPI:

选择Yes后确认,打开rpi的SPI。
重启后检查spi是否被正确加载:
# lsmod | grep spi
spidev 7034 0
spi_bcm2835 7424 0
RPI Configuration
crontab中修改了/bin/pdnsd/sh文件,
/etc/rc.local文件中去掉了有关redsocks和pdnsd的选项。之后重启。
Python示例
可以参考:
https://pimylifeup.com/raspberry-pi-rfid-rc522/
NodeJS例子
# mkdir RFID
# cd RFID
# wget http://node-arm.herokuapp.com/node_latest_armhf.deb
# dpkg -i node_latest_armhf.deb
Aug 29, 2018
Technology离线部署方案说起来很简单,做起来比较繁琐,把Internet连上一次部署成功,再断开后部署成功一次,那下次就直接能用了。
在线状态
前提条件,全翻墙网络,修改Vagrantfile中的操作镜像版本为centos,
网络接口为calico:
...
$os = "centos"
...
$network_plugin = "calico"
...
因为我们用的centos默认是不缓存安装包的,因而在/etc/yum.conf中需要手动打开其缓存包目录:
# vim /etc/yum.conf
cachedir=/var/cache/yum/$basearch/$releasever
keepcache=1
在线部署一次,只要能成功,那么/var/cache/yum/下将缓存所有的rpm包
离线部署
拷贝出一个新的离线部署目录,并删除该目录下的.vagrant目录,并修改vagrant的主机名称,否则默认会使用一样的主机名来部署系统, 为避免网络冲突,应该更改离线环境的网段为新网段.
# cp -r kubespray kubespray_centos_offline
# vim Vagrantfile
$instance_name_prefix = "k8s-offline-centos"
$subnet = "172.17.89"
断开Internet连接, vagrant up设置初始化环境。显然会卡在第一步, yum仓库更新.
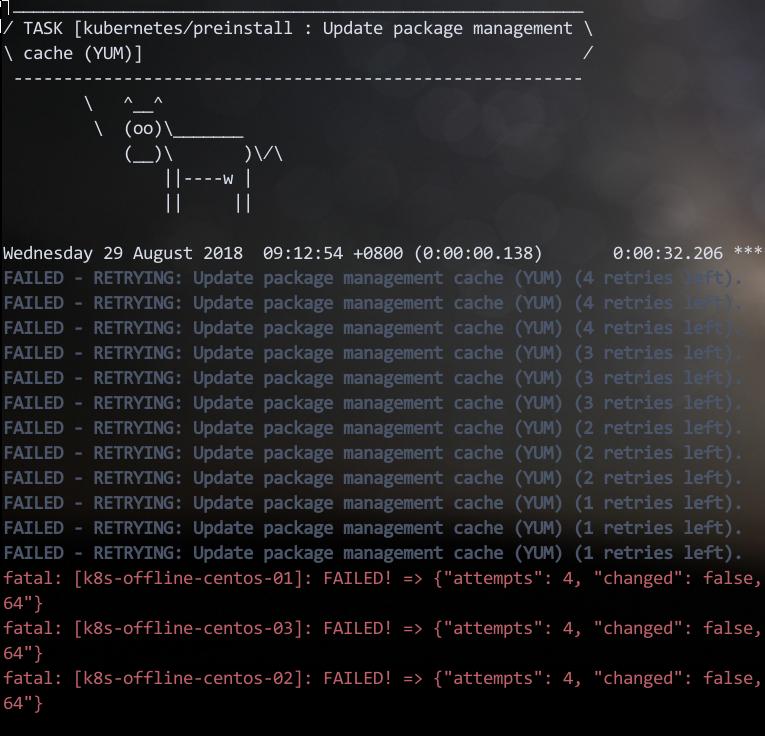
离线yum仓库
在一台在线部署成功的机器上运行以下命令以取回包:
# mkfit /home/vagrant/kubespray_pkgs_ubuntu/
# find . | grep rpm$ | xargs -I % cp % /home/vagrant/kubespray_pkgs_ubuntu/
# createrepo_c .
# scp -r kubespray_pkgs_ubuntu root@172.17.89.1:/web-server-folder
修改ansible playbook:
# vim ./roles/kubernetes/preinstall/tasks/main.yml
- name: Update package management repo address (YUM)
shell: mkdir -p /root/repoback && mv /etc/yum.repos.d/*.repo /root/repoback && curl http://172.17.88.1/kubespray_pkgs_ubuntu/kubespray.repo>/etc/yum.repos.d/kubespray.repo
- name: Update package management cache (YUM)
继续安装, 会在安装docker处失败。
Docker安装
默认会添加docker.repo定义,因为我们在以前已经离线缓存了docker包,这里注释掉:
# vim ./roles/kubernetes/preinstall/tasks/main.yml
#- name: Configure docker repository on RedHat/CentOS
# template:
# src: "rh_docker.repo.j2"
# dest: "{{ yum_repo_dir }}/docker.repo"
# when: ansible_distribution in ["CentOS","RedHat"] and not is_atomic
接下来继续安装,会在Download containers if pull is required or told to always pull (all nodes)处失败.
Docker镜像
offline的情形还没有试出来,暂时禁止自动下载,手动上传到节点。
# vim roles/download/defaults/main.yml
# Used to only evaluate vars from download role
skip_downloads: True
在线节点上,保存离线镜像的脚本:
docker save gcr.io/google-containers/hyperkube-amd64:v1.11.2>1.tar
docker save quay.io/calico/node:v3.1.3>2.tar
docker save quay.io/calico/ctl:v3.1.3>3.tar
docker save quay.io/calico/kube-controllers:v3.1.3>4.tar
docker save quay.io/calico/cni:v3.1.3>5.tar
docker save nginx:1.13>6.tar
docker save gcr.io/google_containers/k8s-dns-dnsmasq-nanny-amd64:1.14.10>7.tar
docker save gcr.io/google_containers/k8s-dns-kube-dns-amd64:1.14.10>8.tar
docker save gcr.io/google_containers/k8s-dns-sidecar-amd64:1.14.10>9.tar
docker save quay.io/coreos/etcd:v3.2.18>9.tar
docker save gcr.io/google_containers/cluster-proportional-autoscaler-amd64:1.1.2>10.tar
docker save gcr.io/google_containers/pause-amd64:3.0>11.tar
Portus镜像仓库配置
参考:
https://purplepalmdash.github.io/blog/2018/05/30/synckismaticimages/
创建team:
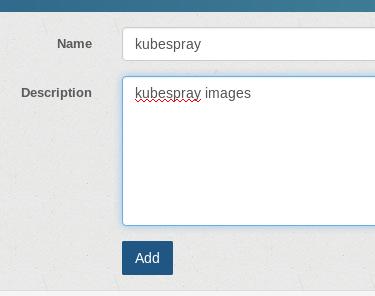
Admin->User->Create new user, 创建一个名为kubespray的用户:
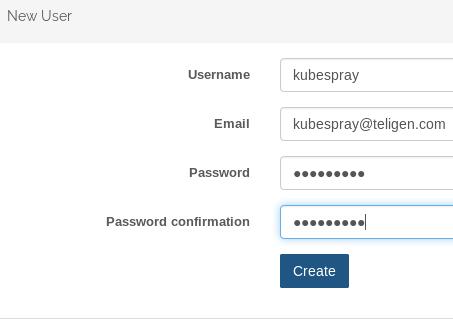
Team->kubespray, Add memeber:
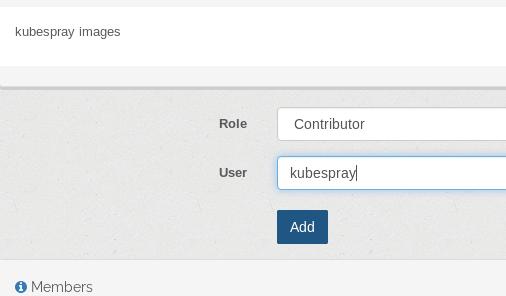
创建一个新的命名空间kubesprayns,并绑定到kubespray组:
查看Log:
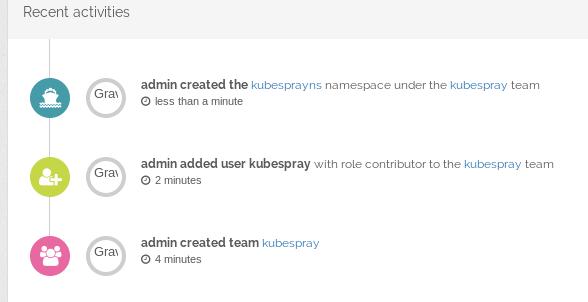
同步镜像到仓库
首先登录到我们刚才创建的仓库:
# docker login portus.xxxx.com:5000/kubesprayns
Username: kubespray
Password: xxxxxxx
Login Succeeded
加载我们之前离线的镜像, 加tag, push.
# for i in `ls *.tar`; do docker load<$i; done
# ./tag_and_push.sh
脚本如下:
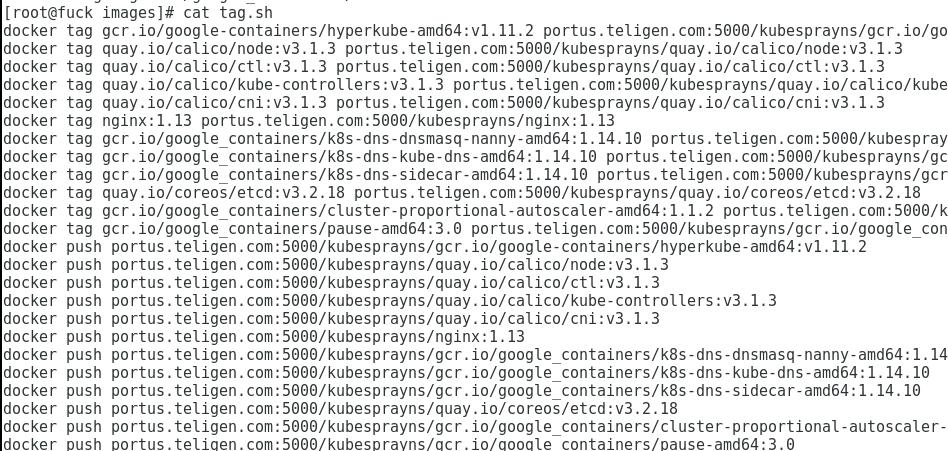
之后我们可以获得纯净的/var/lib/portus目录用于部署kubespray.
接下来替换掉原有的编译脚本,编译出新的ISO
TODO: ansible需要安装, rpm包安装.
ansible部署
起先用vagrant做的一键部署方案,如今需要手动构建出一个集群的定义文件。
Aug 23, 2018
TechnologyProblem
br0->eth0, kvm bridged to br0.
br0: 192.192.189.128
kvm vm address: 192.192.189.109
vm->ping->br0, OK
vm->ping->192.192.189.24/0, Failed
Investigation
Examine the forward and ebtables:
# cat /proc/sys/net/ipv4/ip_forward
1
# ebtables -L
Should be ACCEPT
Use following command for examine the dropped package:
# iptables -x -v --line-numbers -L FORWARD
DOCKER-ISOLATION
Not because of the docker forward, but we have to add br0->br0 rules
Solution
Add one rule:
# iptables -A FORWARD -i br0 -o br0 -j ACCEPT
# apt-get install iptables-persistent
# vim /etc/iptables/rules.v4
*filter
-A FORWARD -i br0 -o br0 -j ACCEPT
COMMIT
Further(Multicast)
Add rc.local systemd item:
# vim /etc/systemd/system/rc-local.service
[Unit]
Description=/etc/rc.local
ConditionPathExists=/etc/rc.local
[Service]
Type=forking
ExecStart=/etc/rc.local start
TimeoutSec=0
StandardOutput=tty
RemainAfterExit=yes
SysVStartPriority=99
[Install]
WantedBy=multi-user.target
The /etc/rc.local should be like following:
#!/bin/sh -e
#
# rc.local
#
# This script is executed at the end of each multiuser runlevel.
# Make sure that the script will "exit 0" on success or any other
# value on error.
#
# In order to enable or disable this script just change the execution
# bits.
#
# By default this script does nothing.
exit 0
Use chmod 777 /etc/rc.local to let it executable.
Systemd enable and run:
# systemctl enable rc-local
# systemctl start rc-local
Enable multicast, add one line into /etc/rc.local:
# vim /etc/rc.local
...
echo "0">/sys/class/net/br0/bridge/multicast_snooping
exit 0
