
TipsOnAIMachine
May 24, 2019Technology
硬件环境
新购的神舟, Z7-KP7GH, CPU, i7-8750H, 内存24G, 显卡Nvidia GTX1060 6G.
8G 优盘用于系统安装.
软件安装及适配
ubuntu-18.04.2-desktop-amd64.iso, 写入优盘:
# sudo dd if=./ubuntu-18.04.2-desktop-amd64.iso of=/dev/sdc bs=1M && sudo sync
笔记本开机按DEL进入BIOS配置,选择U盘启动,遇到安装卡住的问题,解决方案如下:
GRUB choose the Ubuntu, or Install Ubuntu (it depends, you will see it hopefully), go to it with the arrows and press the 'e' key.
Here go to the line which contains quiet splash at the end and add acpi=off after these words.
Then press F10 to boot with these settings.
安装中需要重新分区, 参考:
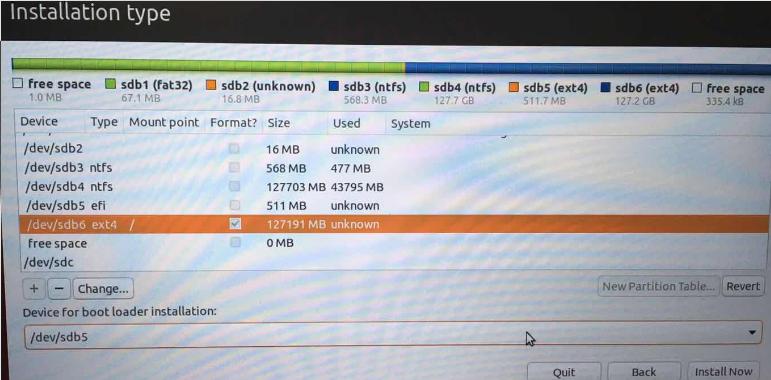 这里新建了efi分区,并使用新建的分区用于安装操作系统,同时保留了原有的Windows操作系统,特别要注意的是关于bootloader的安装位置。
这里新建了efi分区,并使用新建的分区用于安装操作系统,同时保留了原有的Windows操作系统,特别要注意的是关于bootloader的安装位置。
安装完毕后,由于是nvidia卡的原因,首次进入系统会卡住,这里我们需要再次修改GRUB进入系统:
When you are in the GRUB menu, press E to enter the GRUB editor. Add nouveau.modeset=0 to the end of the line that starts with linux. After you've added it, press F10 to boot. Your system should start. After that, go to System Settings > Software & Updates > Additional Drivers and then select the NVIDIA driver. Right now I'm using NVIDIA binary driver- version 367.57 from nvidia-367 (proprietary, tested).
当前(2019-05-24)时,nvidia的驱动是nvida-driver-390.
现在重新启动机器,就可以正常进入系统并执行操作了。
显卡的测试可以参考https://linuxconfig.org/benchmark-your-graphics-card-on-linux
时间的关系这里我就不做了。
系统适配
安装必要的包:
# apt-get install -y openssh-server vim net-tools virt-manager vagrant
vagrant-libvirt meld lm_sensors
Install cuda:
# systemctl stop gdm
# ./cuda_10.0.130_410.48_linux.run
# vim ~/.bashrc
export PATH=/usr/local/cuda-10.0/bin:$PATH
# source ~/.bashrc
# nvidia-smi
Mon May 27 08:40:56 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.48 Driver Version: 410.48 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 1060 Off | 00000000:01:00.0 Off | N/A |
| N/A 55C P0 25W / N/A | 0MiB / 6078MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
# nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2018 NVIDIA Corporation
Built on Sat_Aug_25_21:08:01_CDT_2018
Cuda compilation tools, release 10.0, V10.0.130
# wget xxxxxxxxhttps://developer.nvidia.com/rdp/cudnn-archive
# Get the following packages: cudnn-10.0-linux-x64-v7.5.0.56.tgz
# tar -zxvf cudnn-10.0-linux-x64-v7.4.2.24.tgz
# 拷贝
$ cd cudnn-10.0-linux-x64-v7.4.2.24
$ sudo cp cuda/include/cudnn.h /usr/local/cuda-10.0/include
$ sudo cp cuda/lib64/libcudnn* /usr/local/cuda-10.0/lib64
# 修改权限
$ sudo chmod a+r /usr/local/cuda-10.0/include/cudnn.h /usr/local/cuda-10.0/lib64/libcudnn*
$ vim ~/.bashrc
export LD_LIBRARY_PATH=/usr/local/cuda-10.0/lib64:$LD_LIBRARY_PATH
export CUDNN_PATH="/usr/local/cuda-10.0/lib64/libcudnn.so"
$ source ~/.bashrc
$ echo -e '#include"cudnn.h"\n void main(){}' | nvcc -x c - -o /dev/null -lcudnn
$ echo $?
0
Now upgrading your nvidia driver:
$ sudo add-apt-repository ppa:graphics-drivers/ppa
$ sudo apt update
$ ubuntu-drivers devices
$ sudo ubuntu-drivers autoinstall
$ sudo reboot
After reboot....
$ nvidia-smi
Mon May 27 09:07:16 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 430.14 Driver Version: 430.14 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 1060 Off | 00000000:01:00.0 Off | N/A |
| N/A 49C P0 26W / N/A | 166MiB / 6078MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1970 G /usr/lib/xorg/Xorg 94MiB |
| 0 2148 G /usr/bin/gnome-shell 69MiB |
+-----------------------------------------------------------------------------+
Now your cuda and cudnn is installed OK. Cause nvidia’s cuda will be older than the ppa’s and will cause problems, we need to install driver after cuda installation.
tensorflow
Install pip and use pip for installing tensorflow:
$ sudo apt-get install -y python-pip
$ pip install tensorflow-gpu
$ vim test.py
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
print(sess.run(hello))
$ python test.py
2019-05-27 09:35:27.847206: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2019-05-27 09:35:27.952455: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-05-27 09:35:27.953302: I tensorflow/compiler/xla/service/service.cc:150] XLA service 0x5643333f0dc0 executing computations on platform CUDA. Devices:
2019-05-27 09:35:27.953344: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (0): GeForce GTX 1060, Compute Capability 6.1
2019-05-27 09:35:27.974107: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 2208000000 Hz
2019-05-27 09:35:27.975517: I tensorflow/compiler/xla/service/service.cc:150] XLA service 0x564333ab33b0 executing computations on platform Host. Devices:
2019-05-27 09:35:27.975563: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (0): <undefined>, <undefined>
2019-05-27 09:35:27.977344: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1433] Found device 0 with properties:
name: GeForce GTX 1060 major: 6 minor: 1 memoryClockRate(GHz): 1.6705
pciBusID: 0000:01:00.0
totalMemory: 5.94GiB freeMemory: 5.68GiB
2019-05-27 09:35:27.977382: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1512] Adding visible gpu devices: 0
2019-05-27 09:35:27.979140: I tensorflow/core/common_runtime/gpu/gpu_device.cc:984] Device interconnect StreamExecutor with strength 1 edge matrix:
2019-05-27 09:35:27.979179: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 0
2019-05-27 09:35:27.979193: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003] 0: N
2019-05-27 09:35:27.979313: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 5517 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1060, pci bus id: 0000:01:00.0, compute capability: 6.1)
Hello, TensorFlow!
remote machine
Settings-> Sharing-> Screen Sharing:
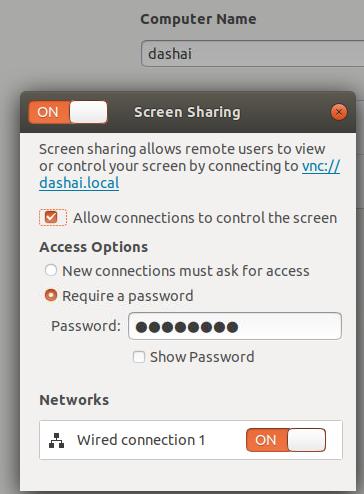
then setting:
$ gsettings set org.gnome.Vino require-encryption false
Now use vncviewer for viewing the 5900 port, you will get the remote screen.