
TipsOnARMVirtManager
Jun 25, 2019Technology
Install following packages:
# apt-get install -y virt-manager
# sudo apt-get install -y qemu-efi-aarch64 qemu-efi-arm ovmf
Install following packages:
# apt-get install -y virt-manager
# sudo apt-get install -y qemu-efi-aarch64 qemu-efi-arm ovmf
Find how many disks are available in system:
# fdisk -l
Examine the detailed info:
# lsblk -o NAME,SIZE,FSTYPE,TYPE,MOUNTPOINT
NAME SIZE FSTYPE TYPE MOUNTPOINT
loop0 876.9M iso9660 loop /media/cdrom
sda 557.9G disk
├─sda1 512M vfat part /boot/efi
└─sda2 557.4G ext4 part /
sdb 3.7T disk
sdc 3.7T disk
sdd 3.7T disk
sde 3.7T disk
sdf 3.7T disk
sdg 3.7T disk
sdh 3.7T disk
sdi 3.7T disk
sdj 3.7T disk
sdk 3.7T disk
sdl 3.7T disk
sdm 3.7T disk
Create the raid10 using following command:
# mdadm --create --verbose /dev/md0 --level=10 --raid-devices=12 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf /dev/sdg /dev/sdh /dev/sdi /dev/sdj /dev/sdk /dev/sdl /dev/sdm
View the status, now you could use it:
# cat /proc/mdstat
Make filesystem for using:
# mkfs.ext4 -F /dev/md0
Create mount point and mount the md0:
# mkdir -p /media/md0
# mount /dev/md0 /media/md0
# df -h
Add md items to mdadm configuration file, so next time bootup kernel will recognize it, also add fstab items:
# mdadm --detail --scan | sudo tee -a /etc/mdadm/mdadm.conf
# cat /etc/mdadm/mdadm.conf
# update-initramfs -u
# echo '/dev/md0 /mnt/md0 ext4 defaults,nofail,discard 0 0' | sudo tee -a /etc/fstab
# cat /etc/fstab
Now view the lsblk output will show like following:
lsblk -o NAME,SIZE,FSTYPE,TYPE,MOUNTPOINT
NAME SIZE FSTYPE TYPE MOUNTPOINT
loop0 876.9M iso9660 loop /media/cdrom
sda 557.9G disk
├─sda1 512M vfat part /boot/efi
└─sda2 557.4G ext4 part /
sdb 3.7T linux_raid_member disk
└─md0 21.9T ext4 raid10 /media/md0
sdc 3.7T linux_raid_member disk
└─md0 21.9T ext4 raid10 /media/md0
sdd 3.7T linux_raid_member disk
└─md0 21.9T ext4 raid10 /media/md0
sde 3.7T linux_raid_member disk
└─md0 21.9T ext4 raid10 /media/md0
sdf 3.7T linux_raid_member disk
└─md0 21.9T ext4 raid10 /media/md0
sdg 3.7T linux_raid_member disk
└─md0 21.9T ext4 raid10 /media/md0
sdh 3.7T linux_raid_member disk
└─md0 21.9T ext4 raid10 /media/md0
sdi 3.7T linux_raid_member disk
└─md0 21.9T ext4 raid10 /media/md0
sdj 3.7T linux_raid_member disk
└─md0 21.9T ext4 raid10 /media/md0
sdk 3.7T linux_raid_member disk
└─md0 21.9T ext4 raid10 /media/md0
sdl 3.7T linux_raid_member disk
└─md0 21.9T ext4 raid10 /media/md0
sdm 3.7T linux_raid_member disk
└─md0 21.9T ext4 raid10 /media/md0
via:
sudo mdadm --stop /dev/md0
sudo mdadm --detail /dev/md0
sudo mdadm --zero-superblock /dev/sdx
sudo mv /etc/mdadm/mdadm.conf /etc/mdadm/mdadm.conf.bak
Install uml-utilites for arm emulator networking:
# sudo apt-get install -y uml-utilities
# sudo tunctl -u dash -t tap0
# sudo ifconfig tap0 192.168.101.1 up
# echo 1 > /proc/sys/net/ipv4/ip_forward
# iptables -t nat -A POSTROUTING -o enp0s20f0u12u1 -j MASQUERADE
# iptables -I FORWARD 1 -i tap0 -j ACCEPT
# iptables -I FORWARD 1 -o tap0 -m state --state RELATED,ESTABLISHED -j ACCEPT
Now your tap0 will be ready for working.
Install qemu for aarch64:
# apt-get install qemu-system-arm
# which qemu-system-aarch64
/usr/bin/qemu-system-aarch64
Using emulator via:
qemu-system-aarch64 -m 6024 -cpu cortex-a57 -M virt -nographic -pflash flash0.img -pflash flash1.img -drive if=none,file=bionic-server-cloudimg-arm64.img,id=hd0 -device virtio-blk-device,drive=hd0 -drive file=user-data.img,format=raw -net nic -net tap,ifname=tap0,script=no #-device virtio-net-device,netdev=net0,mac=52:54:00:12:34:56
Too slow on x86. So I switches to arm based server.
Mount iso and use it as the repository server:
# mount -t iso9660 -o loop ubuntu-18.04.2-server-arm64.iso /mnt
# apt-cdrom -d=/mnt add
# cat /etc/apt/sources.list
deb cdrom:[Ubuntu-Server 18.04.2 LTS _Bionic Beaver_ - Release arm64 (20190210)]/ bionic main r
estricted
# apt-get update -y
# cp ubuntu-18.04.2-server-arm64.iso ubuntu-18.04.2-server-arm64-1.iso
# mount -t iso9660 -o loop ./ubuntu-18.04.2-server-arm64-1.iso /media/cdrom
Install some packages for qemu:
# apt-get install -y qemu-kvm build-essential
When offline, we use the offline repository:
# cd /root/armdebs
# dpkg-scanpackages . /dev/null | gzip -9c > Packages.gz
# vim /etc/apt/sources.list
deb [trusted=yes] file:///home/test/armdebs ./
# apt-get update -y
# apt-get install -y uml-utilities
From now on we could use qemu-kvm for accessing our vm.
Run emulated vms and install kubernetes, successful.
Notice, you should run following(pip download) on arm based machine!!!
On phsical machine, do following steps:
# apt-get install -y python-pip
# mkdir piparmarm
# cd piparmarm/
# pip download ansible
# pip download httplib2
Transfer the piparmarm folder to your machine, install it via:
root@arm01:~/piparmarm# pip install --no-index --find-links /home/test/piparmarm/ ansible httplib2
root@arm01:~/piparmarm# which ansible
/usr/local/bin/ansible
root@arm01:~/piparmarm# ansible --version
ansible 2.8.1
config file = None
configured module search path = [u'/home/test/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules']
ansible python module location = /usr/local/lib/python2.7/dist-packages/ansible
executable location = /usr/local/bin/ansible
python version = 2.7.15rc1 (default, Nov 12 2018, 14:31:15) [GCC 7.3.0]
Install docker-ce(manually):
# apt-get install -y docker-ce python-netaddr
# docker load<allimages.tar
Configure the hosts.ini, then run playbook:
# ansible-playbook -i inventory/sample/hosts.ini cluster.yml
helm docker image doesn’t support arm64, thus we do following steps for rebuilding our own image:
# wget https://storage.googleapis.com/kubernetes-helm/helm-${HELM_LATEST_VERSION}-linux-arm64.tar.gz
# tar xzvf helm-xxxxx-linux-arm64.tar.gz
# mv linux-arm64/helm ~/dockerbuild
# cd ~/dockerbuild
# vim Dockerfile
The Dockerfile we changes to following:
FROM alpine
LABEL maintainer="Lachlan Evenson <lachlan.evenson@gmail.com>"
ARG VCS_REF
ARG BUILD_DATE
# Metadata
LABEL org.label-schema.vcs-ref=$VCS_REF \
org.label-schema.vcs-url="https://github.com/lachie83/k8s-helm" \
org.label-schema.build-date=$BUILD_DATE \
org.label-schema.docker.dockerfile="/Dockerfile"
ENV HELM_LATEST_VERSION="v2.13.1"
COPY . /usr/local/bin
ENTRYPOINT ["helm"]
CMD ["help"]
Build the image with following commands:
# docker image build -t lachlanevenson/k8s-helm:v2.13.1-arm64 .
# docker save -o helmarm.tar lachlanevenson/k8s-helm:v2.13.1-arm64
Using the arm64 based image we could setup helm on kubespray.
Install docker-compose via:
# pip download docker-compose
# Install docker-compose in offline environment.
Clone the repository and extract it to:
# pwd
/home/dash/Downloads/harbor-arm64/harbor-arm64-develop
# cd make
# ls
checkenv.sh docker-compose.clair.yml harbor.cfg prepare
common docker-compose.notary.tpl install.sh pushimage.sh
docker-compose.chartmuseum.tpl docker-compose.notary.yml kubernetes
docker-compose.chartmuseum.yml docker-compose.tpl migrations
docker-compose.clair.tpl docker-compose.yml photon
The docker-compose file exists under folder.
changed to using repository’s docker-compose. apt-get install -y docker-compose.
Download and install Vmware workstation pro on Ubuntu:
# wget https://download3.vmware.com/software/wkst/file/VMware-Workstation-Full-15.1.0-13591040.x86_64.bundle
# chmod 777 *.bundle
# ./VMware-Workstation-Full-15.1.0-13591040.x86_64.bundle
Create a new machine:

Select iso:
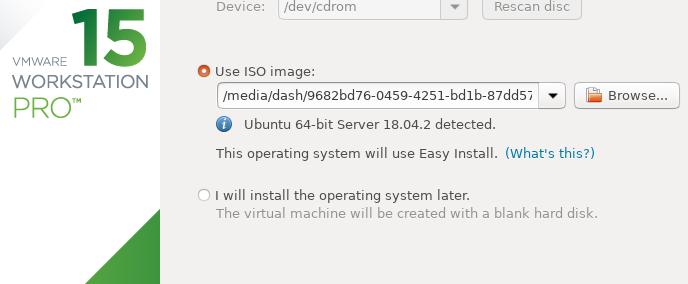
Personalize Linux:
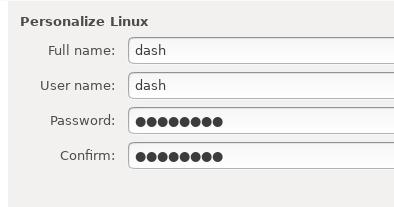
Select location:
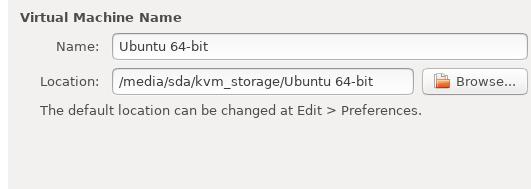
Specify processor:

Specify Memory:

Specify NAT:

I/O Controller:
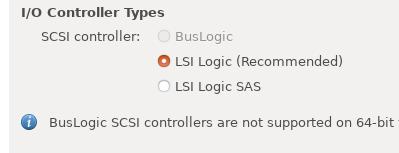
Virtual Disk Type:

Create a new disk:

Specify 200GB:
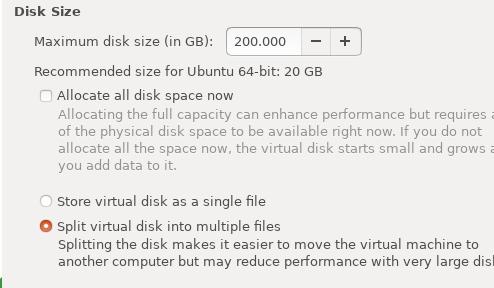
Disk File:
Click Finish and begin installation.
When installation, click poweroff, and setting , remove the auto install iso:
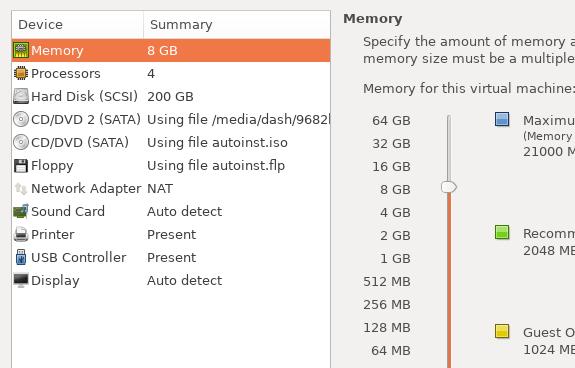
Uncheck Connect at power on for both Floppy and CD/DVD(SATA), then reboot, you will see
our customized installation items, use them for installing:
After installation, check the configured ip address:
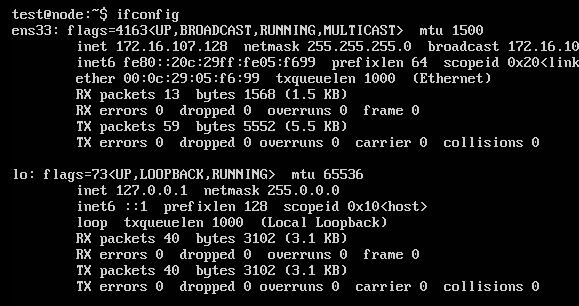
Default grub configuration:
# vim /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="net.ifnames=0 biosdevname=0"
# grub-mkconfig -o /boot/grub/grub.cfg
# vim /etc/netplan/01-netcfg.yaml
eth0:
dhcp4: no
addresses: [172.16.107.17/24]
gateway4: 172.16.107.2
Then reboot and use our ansible code for deploying.
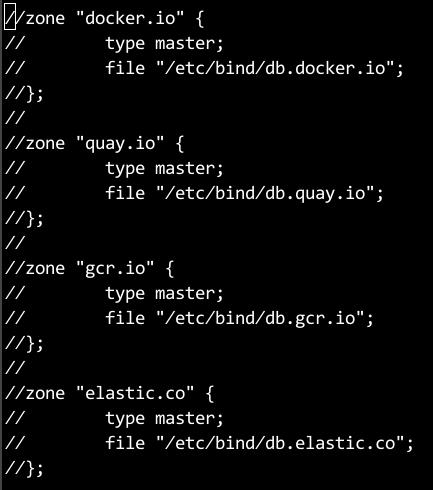
Remove the dns items for docker.io, quay.io, gcr.io, elastic.co:
vim /etc/bind/named.conf.default-zones:
logout from our fake website:
root@node0:/home/test# docker logout quay.io
Removing login credentials for quay.io
root@node0:/home/test# docker logout gcr.io
Removing login credentials for gcr.io
root@node0:/home/test# docker logout k8s.gcr.io
Removing login credentials for k8s.gcr.io
root@node0:/home/test# docker logout docker.elastic.co
Removing login credentials for docker.elastic.co
root@node0:/home/test# docker logout
Remove the crt files and update the ca certification:
# cd /usr/local/share/ca-certificates/
# mv server.crt /root
# update-ca-certificates
# cd /etc/ssl/
# cd certs/
# rm -f server.pem
# update-ca-certificates
Then remove the items for bind9.
Now reboot the machine.
Rongv1905部署就绪的集群,运行操作系统为ubuntu18.04.2.
AI部署框架使用ansible撰写。目录架构如下, 配置好hosts.ini:
# ls
ai.yaml ansible.cfg deploy.key hosts.ini roles
# cat hosts.ini
[all]
localnode-2 ansible_host=10.142.18.192 ansible_port=22 ansible_user='root' ansible_ssh_private_key_file=./deploy.key ip=10.142.18.192 ansible_ssh_user=root
localnode-3 ansible_host=10.142.18.193 ansible_port=22 ansible_user='root' ansible_ssh_private_key_file=./deploy.key ip=10.142.18.193 ansible_ssh_user=root
localnode-1 ansible_host=10.142.18.191 ansible_port=22 ansible_user='root' ansible_ssh_private_key_file=./deploy.key ip=10.142.18.191 ansible_ssh_user=root
[kube-deploy]
localnode-[1:1]
[kube-master]
localnode-[1:1]
部署命令:
# ansible-playbook -i hosts.ini ai.yaml
部署完毕后,通过kubectl get pods命令查看当前集群中运行的kubeflow相关组件:
# kubectl get pods
NAME READY STATUS RESTARTS AGE
ambassador-7df7dbd89b-64q5b 2/2 Running 0 2m
ambassador-7df7dbd89b-b97w6 2/2 Running 0 2m
ambassador-7df7dbd89b-gcdq7 2/2 Running 0 2m
centraldashboard-5d7d79659c-dr29w 1/1 Running 0 2m
inception-v1-d66f8848-lgz97 1/1 Running 0 103s
pytorch-operator-7b7958b799-vmks4 1/1 Running 0 88s
spartakus-volunteer-779867878-snvxz 1/1 Running 0 2m
tf-hub-0 1/1 Running 0 2m
tf-job-dashboard-554868c978-cknlz 1/1 Running 0 2m
tf-job-operator-v1alpha2-7f7cf4dc98-9txms 1/1 Running 0 2m
通过kubectl get svc查看kubeflow引出的相关服务:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ambassador ClusterIP 10.233.35.161 <none> 80/TCP 28m
ambassador-admin ClusterIP 10.233.8.245 <none> 8877/TCP 28m
ambassador-katacoda NodePort 10.233.38.151 <none> 30080:30396/TCP 3s
centraldashboard ClusterIP 10.233.29.157 <none> 80/TCP 28m
centraldashboard-katacoda NodePort 10.233.9.5 <none> 8082:31421/TCP 3s
k8s-dashboard ClusterIP 10.233.3.208 <none> 443/TCP 28m
kubernetes ClusterIP 10.233.0.1 <none> 443/TCP 19d
tf-hub-0 ClusterIP None <none> 8000/TCP 28m
tf-hub-lb ClusterIP 10.233.32.120 <none> 80/TCP 28m
tf-hub-lb-katacoda NodePort 10.233.13.173 <none> 80:31039/TCP 3s
tf-job-dashboard ClusterIP 10.233.22.155 <none> 80/TCP 28m
使用浏览器访问相应端口:
centraldashboard-katacoda: 31421, ambassador-katacoda: 30396:
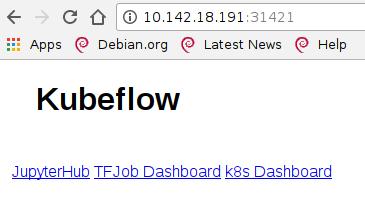
tf-hub-lb-katacoda:
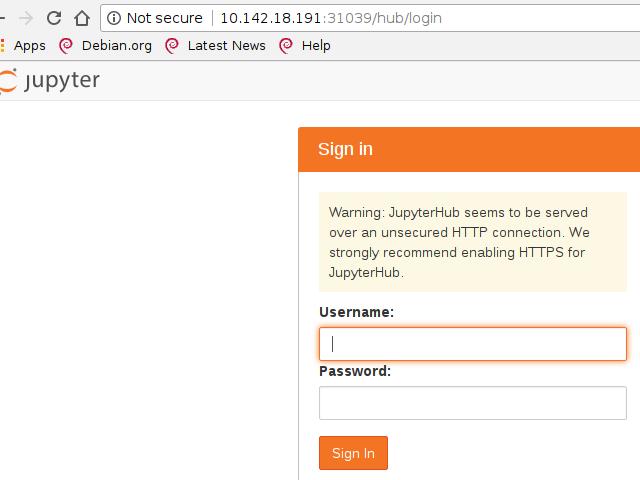
Kubeflow的关键组件之一是能够通过JupyterHub运行Jupyter笔记本电脑。 Jupyter Notebook是经典的数据科学工具,用于在浏览器中记录流程时运行内联脚本和代码片段。
可以使用kubectl get svc找到Load Balancer的IP地址,
Jypyter的登录默认使用用户名admin和空白密码:
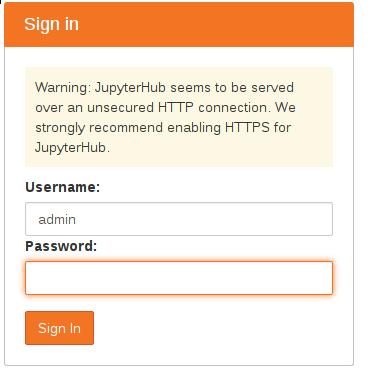
在弹出的Spawner Options中,我们填入下列字段。
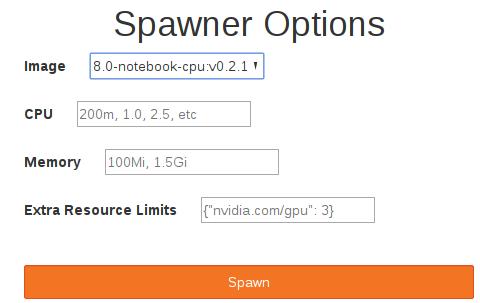
Kubeflow在内部使用gcr.io/kubeflow-images-public/tensorflow-1.8.0-notebook-cpu:v0.2.1 Docker Image作为默认值。访问JupyterHub后,可以单击 Start My server按钮:
root@localnode-1:~# kubectl get pods -o wide | grep jupyter-admin
jupyter-admin 1/1 Running 0 39s 10.233.125.9 localnode-1 <none> <none>
Spawn完毕后界面如下:
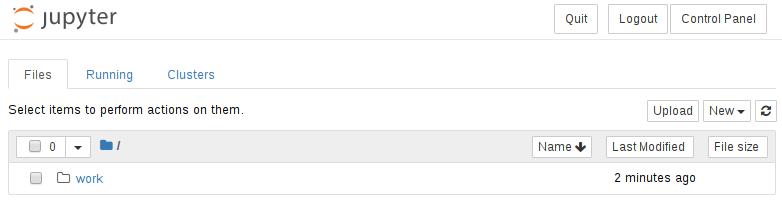
现在可以通过pod访问JupyterHub。您现在可以无缝地使用环境。例如,要创建新笔记本,请选择New下拉列表,然后选择Python 3内核,如下所示。
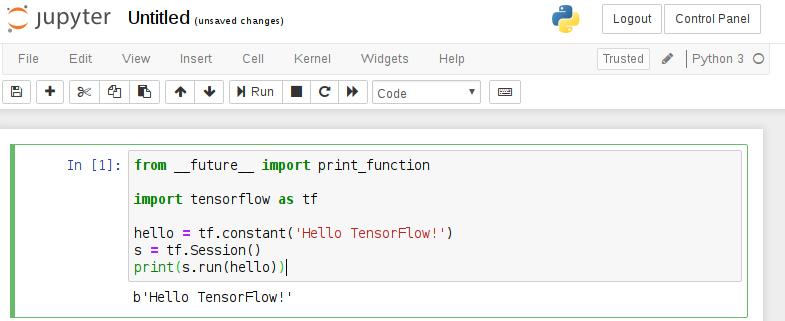
现在可以创建代码片段。要开始使用TensorFlow,请将下面的代码粘贴到第一个单元格并运行它。
from __future__ import print_function
import tensorflow as tf
hello = tf.constant('Hello TensorFlow!')
s = tf.Session()
print(s.run(hello))
运行结果如下:
TfJob提供了一个Kubeflow自定义资源,可以在Kubernetes上轻松运行分布式或非分布式TensorFlow作业。 TFJob控制器为master,parameter servers和worker采用YAML规范来帮助运行分布式计算。
自定义资源定义(CRD)提供了以与内置Kubernetes资源相同的方式创建和管理TF作业的功能。 部署后,CRD可以配置TensorFlow job,允许用户专注于机器学习而不是基础设施。
要部署上一步中描述的TensorFlow工作负载,Kubeflow需要TFJob定义。 在这种情况下,可以通过运行cat example.yaml来查看它:
apiVersion: "kubeflow.org/v1alpha2"
kind: "TFJob"
metadata:
name: "example-job"
spec:
tfReplicaSpecs:
Master:
replicas: 1
restartPolicy: Never
template:
spec:
containers:
- name: tensorflow
image: gcr.io/tf-on-k8s-dogfood/tf_sample:dc944ff
Worker:
replicas: 1
restartPolicy: Never
template:
spec:
containers:
- name: tensorflow
image: gcr.io/tf-on-k8s-dogfood/tf_sample:dc944ff
PS:
replicas: 2
restartPolicy: Never
template:
spec:
containers:
- name: tensorflow
image: gcr.io/tf-on-k8s-dogfood/tf_sample:dc944ff
以上yaml定义了三个组件:
Master: 每个job必须有一个master. Master将协调workers之间的训练操作的执行.
Worker: 每个job可以有0到N个workers.
每个worker进程运行相同的模型,为参数服务器(Parameter Server)提供处理参数。
PS: 每个job可以有0到N个参数服务器(Parameter Server),
参数服务器使得用户可以将模型扩展到多台机器上。
TFJob可以用以下命令来创建:
# kubectl apply -f example.yaml
通过部署job,Kubernetes将调度工作负载以跨可用节点执行。 作为部署的一部分,Kubeflow将使用所需的设置配置TensorFlow,以允许不同的组件进行通信。
可以通过kubectl get tfjob查看TensorFlow作业的状态。 完成TensorFlow作业后,Master将标记为成功。 继续运行kubectl get tfjob命令以查看它何时完成。
Master负责协调作业的执行,并汇总结果。可以使用kubectl get pods| grep completed列出已完成的工作负载。
# kubectl get pods | grep Completed
example-job-master-0 0/1 Completed 0 7m36s
在此示例中,结果输出到STDOUT,可使用kubectl日志查看。
以下命令将输出结果:
# kubectl logs $(kubectl get pods | grep Completed | tr -s ' ' | cut -d ' ' -f 1)
INFO:root:Tensorflow version: 1.3.0-rc2
INFO:root:Tensorflow git version: v1.3.0-rc1-27-g2784b1c
INFO:root:tf_config: {u'cluster': {u'worker': [u'example-job-worker-0.default.svc.cluster.local:2222'], u'ps': [u'example-job-ps-0.default.svc.cluster.local:2222', u'example-job-ps-1.default.svc.cluster.local:2222'], u'master': [u'example-job-master-0.default.svc.cluster.local:2222']}, u'task': {u'index': 0, u'type': u'master'}}
可以在master, worker以及parameter servers上看到工作负载的执行结果。
一旦训练完成,该模型可用于在新数据发布时对其进行预测。 通过使用Kubeflow,可以通过将作业部署到Kubernetes基础结构,从而使得Model Server变得可用.
Kubeflow tf-serving提供了服务TensorFlow模型的模板。 这可以通过使用Ksonnet定制和部署,并根据您的模型定义参数。
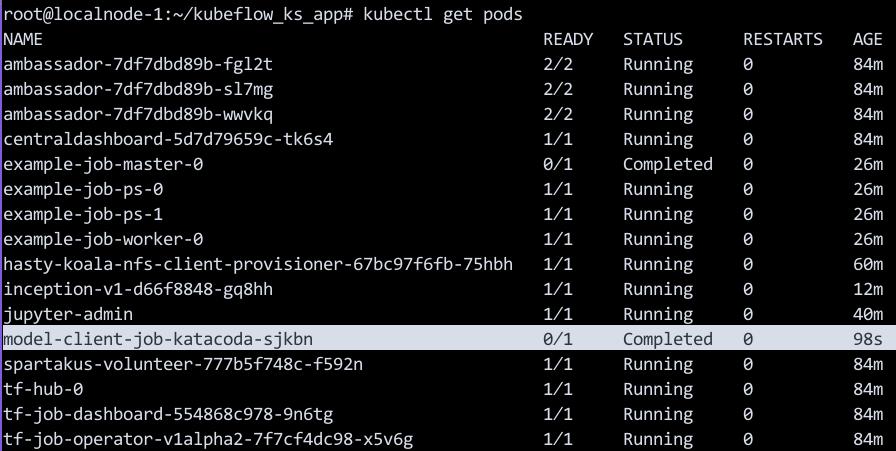
通过部署脚本已经部署完毕Model Server, 客户端可以链接并访问到trained data(训练好的数据), 可以查看pod信息:
kubectl get pods
......
inception-v1-d66f8848-gq8hh 1/1 Running 0 7m2s
......
上面的inception就是我们训练好的模型.
在这个例子中,我们使用预先训练的Inception V3模型。 这是在ImageNet数据集上训练的架构。 ML任务是图像分类,而模型服务器及其客户端由Kubernetes处理。
要使用已发布的模型,您需要设置客户端。 这可以通过与其他工作相同的方式实现。 用于部署客户端的YAML文件可以通过cat ~/model-client-job.yaml来查看。 要部署它,请使用以下命令:
kubectl apply -f ~/model-client-job.yaml
文件内容:
# cat model-client-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: model-client-job-katacoda
spec:
template:
metadata:
name: model-client-job-katacoda
spec:
containers:
- name: model-client-job-katacoda
image: katacoda/tensorflow_serving:localimage
imagePullPolicy: Never
command:
- /bin/bash
- -c
args:
- /serving/bazel-bin/tensorflow_serving/example/inception_client
--server=inception:9000 --image=/data/katacoda.jpg
restartPolicy: Never
如需查看model-client-job运行的状态,则运行:
kubectl get pods
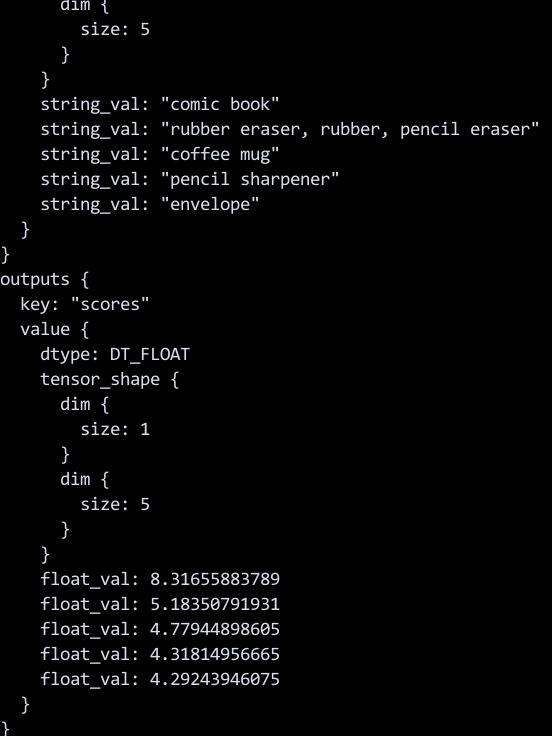
以下命令将输出图像分类的结果:
kubectl logs $(kubectl get pods | grep Completed | tail -n1 | tr -s ' ' | cut -d ' ' -f 1)
Kubeflow使用自定义资源定义(CRD)和运算符扩展了Kubernetes。 每个自定义资源都旨在支持机器学习工作负载的部署。 定义好资源后,Operator将处理部署请求。
使用kubectl get crd命令可以查看到自定义的PyTorch自定义资源已被创建:
# kubectl get crd
NAME CREATED AT
pytorchjobs.kubeflow.org 2019-06-03T04:19:22Z
tfjobs.kubeflow.org 2019-06-03T02:46:43Z
使用打包好的容器镜像启动PyTorch,该镜像中已打包了分布式MNIST模型。模型的python代码可以在以下链接查看:
要部署该训练模型,我们需要创建一个PyTorch Job, PyTorch Job中定义了需使用的容器镜像以及训练所需要启动的副本数, 我们用于启动训练模型的yaml定义文件如下所示:
# cat pytorch_example.yaml
apiVersion: "kubeflow.org/v1alpha1"
kind: "PyTorchJob"
metadata:
name: "distributed-mnist"
spec:
backend: "tcp"
masterPort: "23456"
replicaSpecs:
- replicas: 1
replicaType: MASTER
template:
spec:
containers:
- image: gcr.io/kubeflow-ci/pytorch-dist-mnist_test:1.0
imagePullPolicy: IfNotPresent
name: pytorch
restartPolicy: OnFailure
- replicas: 3
replicaType: WORKER
template:
spec:
containers:
- image: gcr.io/kubeflow-ci/pytorch-dist-mnist_test:1.0
imagePullPolicy: IfNotPresent
name: pytorch
restartPolicy: OnFailure
通过以下命令来创建训练任务:
# kubectl create -f pytorch_example.yaml
Kubeflow PyTorch Operator和Kubernetes将安排工作负载并启动所需数量的副本。 您可以使用kubectl get pods -l pytorch_job_name = distributed-mnist查看状态, 使用此命令将看到一个master和3个worker被创建。
训练应该运行大约10个epochs(时期),并且在CPU群集上需要5-10分钟。可以使用以下命令检查日志以查看训练进度:
PODNAME=$(kubectl get pods -l pytorch_job_name=distributed-mnist,task_index=0 -o name)
kubectl logs ${PODNAME}
输出类似于以下内容:
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Processing...
Done!
Rank 0 , epoch 0 : 1.2745472780232237
Rank 0 , epoch 1 : 0.5743547164872765
您可以通过在节点上使用htop来了解训练如何利用所有的CPU内核。如果我们将其他节点添加到Kubernetes集群,则三个副本将分布在节点上并加快训练时间。
随着训练的进行,可以使用Kubectl查看状态以及训练何时完成。通过以yaml输出作业,可以查看执行的内部细节。这包括状态。
kubectl get -o yaml pytorchjobs distributed-mnist
kubectl get -o json pytorchjobs distributed-mnist | jq .status
kubectl get -o json pytorchjobs distributed-mnist | jq .status.state
训练结束后,结果如下所示:
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Processing...
Done!
Rank 0 , epoch 0 : 1.2745472780232237
Rank 0 , epoch 1 : 0.5743547164872765
Rank 0 , epoch 2 : 0.4351522875810737
Rank 0 , epoch 3 : 0.36984553888662536
Rank 0 , epoch 4 : 0.3216655456038045
Rank 0 , epoch 5 : 0.2951831894356813
Rank 0 , epoch 6 : 0.2750083558114448
Rank 0 , epoch 7 : 0.2595048323273659
Rank 0 , epoch 8 : 0.24862684973521526
Rank 0 , epoch 9 : 0.22692083941101393
可以看到,随着训练的进行,损失逐渐减小。