
RSSToPdf
Dec 29, 2016
Technology
AIM
Using python for fetching back some blog articles and convert them into pdf files, send it to some specified mailbox.
Preparation
The script depends on python library:
- feedparser
- pdfkit
Install them via:
$ sudo pip install feedparser
$ sudo pip install pdfkit
pdfkit depends on wkhtmltopdf, install it on ubuntu via:
$ sudo apt-get install -y wkhtmltopdf
Configure wkhtmltopdf, because in vps we don’t have X Window:
# apt-get install -y ttf-wqy-zenhei xvfb
# echo 'xvfb-run --server-args="-screen 0, 1024x768x24" /usr/bin/wkhtmltopdf $*' > /usr/bin/wkhtmltopdf.sh
# chmod 777 /usr/bin/wkhtmltopdf.sh
# ln -s /usr/bin/wkhtmltopdf.sh /usr/local/bin/wkhtmltopdf
# which wkhtmltopdf
/usr/local/bin/wkhtmltopdf
Script
The python script is listed as following:
import sys
import pdfkit
import feedparser
reload(sys);
sys.setdefaultencoding("utf8")
options = {
'page-size': 'Letter',
'margin-top': '0.75in',
'margin-right': '0.75in',
'margin-bottom': '0.75in',
'margin-left': '0.75in',
'encoding': "UTF-8",
'custom-header' : [
('Accept-Encoding', 'gzip')
],
'cookie': [
('cookie-name1', 'cookie-value1'),
('cookie-name2', 'cookie-value2'),
],
'no-outline': None
}
htmlhead = """
<html>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<head>
<title>BlogList</title>
</head>
<body>
"""
htmltail = """
</body>
</html>
"""
Article = htmlhead
d = feedparser.parse('https://feeds.feedburner.com/letscorp/aDmw')
for post in d.entries:
# Post Title
#print post.title
Article += "<h2>" + post.title + "</h2>"
# Post Content
#print post.content[0].value.rsplit('span', 2)[0][:-4]
#Article += post.content[0].value.rsplit('span', 2)[0][:-4]
Article += post.content[0].value
Article += htmltail
print Article
#pdfkit.from_string(Article, 'output.pdf', options=options)
Unfortunately the last line won’t work, cause we are working under terminal, we use the wrapped wkhtmltopdf, so we comment it, and redirect our output into a html file, manually convert from html to pdf.
Usage
Output pdf via following command:
$ python fetch.py>fetch.html
$ wkhtmltopdf fetch.html output.pdf
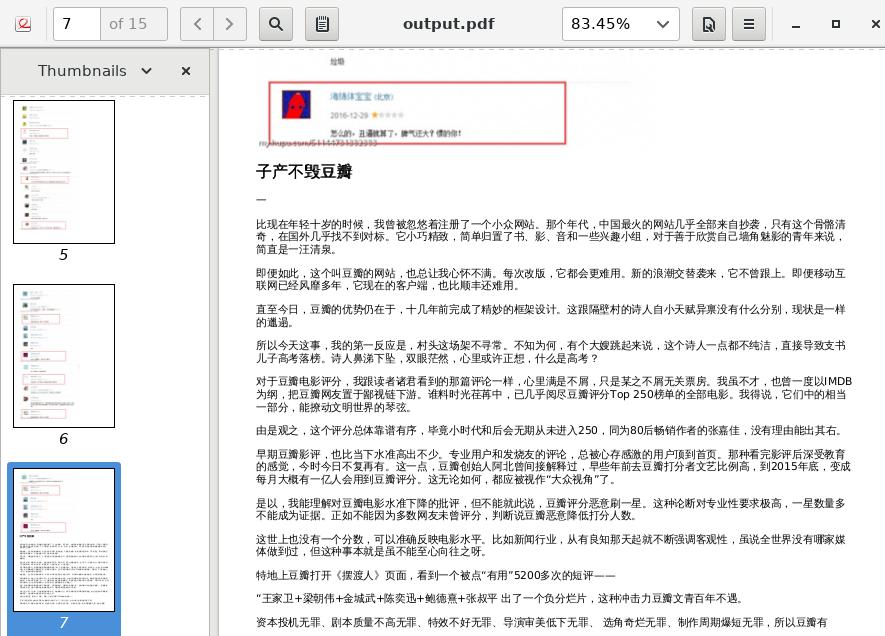
The generated output.pdf contains the latest 10 articles in blog, like
following screenshot image:
Further Works
- Could it fetch more blog items via rss?
- Crontab for sending out pdf as attached files to specified email box?
- Judgement from date?
- Less size of pdf file(shriking the image size)?
- Use CSS for beautify this output pdf?