
WorkingTipsOnGpu
Apr 13, 2021
Technology
1. 环境配置信息
整个验证环境的配置信息如下:
gpumaster: 10.168.100.2 4核16G
gpunode1: 10.168.100.3 4核16G PCI直通B5:00 Tesla V100
gpunode2: 10.168.100.4 4核16G PCI直通B2:00 Tesla V100
节点的操作系统配置如下, CentOS 7.6最小化安装方式:
# uname -a
Linux gpumaster 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
# cat /etc/redhat-release
CentOS Linux release 7.6.1810 (Core)
其中master节点上外挂了一块500G 的数据盘,需要手动挂载至/dcos目录:
[root@gpumaster ~]# df -h | grep dcos
/dev/vdb1 493G 73M 467G 1% /dcos
[root@gpumaster ~]# cat /etc/fstab | grep dcos
/dev/vdb1 /dcos ext4 defaults 0 0
3个节点依次关闭selinux/firewalld:
# vi /etc/selinux/config
...
SELINUX=disabled
...
# systemctl disable firewalld
# reboot
2. 部署CCSE集群
依次添加节点:

新增一个名为gpucluster的集群:
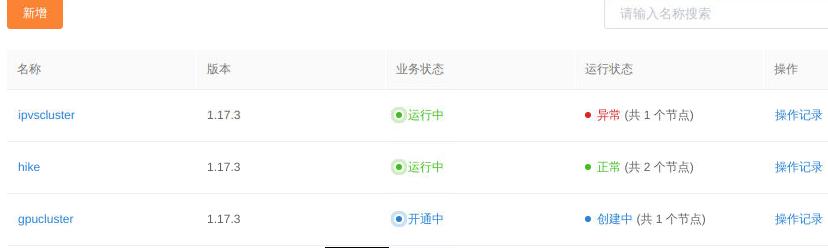
集群创建完毕后,新增两个GPU节点:
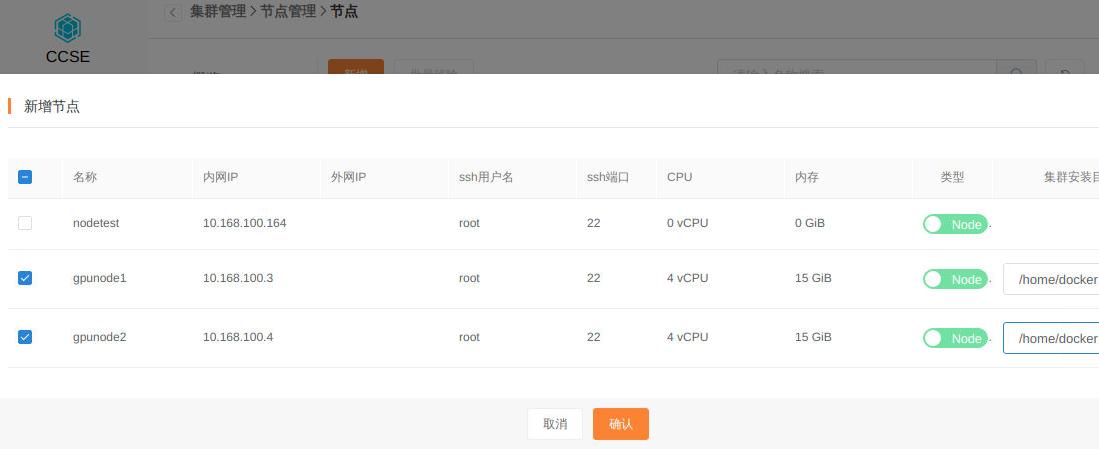
添加完成后,检查集群状态:
[root@gpumaster ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
10.168.100.2 Ready master 6m19s v1.17.3
10.168.100.3 Ready node 78s v1.17.3
10.168.100.4 Ready node 78s v1.17.3
3. 升级内核
在三个节点上,依次执行以下操作以升级内核。
配置离线软件库:
# cd /etc/yum.repos.d
# mkdir back
# mv CentOS-* back
# vi nvidia.repo
[nvidia]
name=nvidia
baseurl=http://10.168.100.144:8200/repo/x86_64/nvidiarpms
gpgcheck=0
enabled=1
proxy=_none_
# yum install -y kernel-ml
配置grub启动:
# vi /etc/default/grub
...
GRUB_DEFAULT=0
...
GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet rd.driver.blacklist=nouveau nouveau.modeset=0"
...
# grub2-mkconfig -o /boot/grub2/grub.cfg
完全禁用系统自带的nouveau驱动:
# echo 'install nouveau /bin/false' >> /etc/modprobe.d/nouveau.conf
执行完上述操作后需重启机器并验证内核是否更改成功:
# uname -a
Linux gpunode2 4.19.12-1.el7.elrepo.x86_64 #1 SMP Fri Dec 21 11:06:36 EST 2018 x86_64 x86_64 x86_64 GNU/Linux
4. gpu-operator文件准备
Harbor中预上传的镜像文件列表如下(nvcr.io及nvidia):
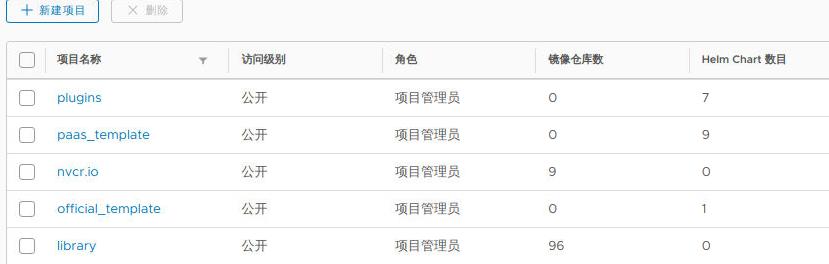
从10.168.100.1上scp以下目录到所有节点:
$ scp -r docker@10.168.100.1:/home/docker/nvidia_items .
预Load nfd镜像:
# docker load<quay.tar
...
Loaded image: quay.io/kubernetes_incubator/node-feature-discovery:v0.6.0
5. 安装NVIDIA/gpu-operator
登录到gpumaster节点,从文件创建一个部署charts时需用到的configmap:
# cat ccse.repo
[ccse-k8s]
name=Centos local yum repo for k8s
baseurl=http://10.168.100.144:8200/repo/x86_64/k8s-offline-pkgs
gpgcheck=0
enabled=1
proxy=_none_
[ccse-centos7-base]
name=Centos local yum repo for k8s
baseurl=http://10.168.100.144:8200/repo/x86_64/centos7-base
gpgcheck=0
enabled=1
proxy=_none_
[fuck]
name=Centos local yum repo for k8s 111
baseurl=http://10.168.100.144:8200/repo/x86_64/nvidiarpms
gpgcheck=0
enabled=1
proxy=_none_
# kubectl create namespace gpu-operator-resources
namespace/gpu-operator-resources created
# kubectl create configmap repo-config -n gpu-operator-resources --from-file=ccse.repo
configmap/repo-config created
现在创建gpu-operator实例:
# cd gpu-operator/
# helm install --generate-name . -f values.yaml
检查实例运行情况:
# kubectl get po
NAME READY STATUS RESTARTS AGE
chart-1618803326-node-feature-discovery-master-655c6997cd-fp465 1/1 Running 0 65s
chart-1618803326-node-feature-discovery-worker-7flft 1/1 Running 0 65s
chart-1618803326-node-feature-discovery-worker-mkqm7 1/1 Running 0 65s
chart-1618803326-node-feature-discovery-worker-w2d44 1/1 Running 0 65s
gpu-operator-945878fff-l22vc 1/1 Running 0 65s
给GPU节点手动添加标签,gpu-operator-resources命名空间下的实例运行情况:
使能GPU驱动安装:
# kubectl label nodes 10.168.100.3 nvidia.com/gpu.deploy.driver=true
node/10.168.100.3 labeled
# kubectl label nodes 10.168.100.4 nvidia.com/gpu.deploy.driver=true
node/10.168.100.4 labeled
检查GPU驱动编译情况:
# kubectl get po -n gpu-operator-resources
NAME READY STATUS RESTARTS AGE
nvidia-driver-daemonset-w6d2q 1/1 Running 0 86s
nvidia-driver-daemonset-zmf9l 1/1 Running 0 86s
# kubectl logs po nvidia-driver-daemonset-zmf9l -n gpu-operator-resources
Installation of the kernel module for the NVIDIA Accelerated Graphics Driver for Linux-x86_64 (version 460.32.03) is now complete.
Loading IPMI kernel module...
Loading NVIDIA driver kernel modules...
Starting NVIDIA persistence daemon...
Mounting NVIDIA driver rootfs...
Done, now waiting for signal
使能device-plugin, dcgm-exporter等:
# kubectl label nodes 10.168.100.4 nvidia.com/gpu.deploy.container-toolkit=true
# kubectl label nodes 10.168.100.4 nvidia.com/gpu.deploy.device-plugin=true
# kubectl label nodes 10.168.100.4 nvidia.com/gpu.deploy.dcgm-exporter=true
# kubectl label nodes 10.168.100.4 nvidia.com/gpu.deploy.gpu-feature-discovery=true
# kubectl label nodes 10.168.100.3 nvidia.com/gpu.deploy.container-toolkit=true
# kubectl label nodes 10.168.100.3 nvidia.com/gpu.deploy.device-plugin=true
# kubectl label nodes 10.168.100.3 nvidia.com/gpu.deploy.dcgm-exporter=true
# kubectl label nodes 10.168.100.3 nvidia.com/gpu.deploy.gpu-feature-discovery=true
检查toolkit-daemonset运行情况,会发现Init:ImagePullBackOff报错信息:
# kubectl get po -n gpu-operator-resources
NAME READY STATUS RESTARTS AGE
nvidia-container-toolkit-daemonset-6kqq5 0/1 Init:ImagePullBackOff 0 2m16s
nvidia-container-toolkit-daemonset-cbww2 0/1 Init:ImagePullBackOff 0 4m1s
# kubectl logs nvidia-container-toolkit-daemonset-cbww2 -n gpu-operator-resources
Normal BackOff 3m31s (x7 over 4m46s) kubelet, 10.168.100.4 Back-off pulling image "10.168.100.144:8021/nvcr.io/nvidia/k8s/cuda@sha256:ed723a1339cddd75eb9f2be2f3476edf497a1b189c10c9bf9eb8da4a16a51a59"
Warning Failed 3m31s (x7 over 4m46s) kubelet, 10.168.100.4 Error: ImagePullBackOff
Normal Pulling 3m20s (x4 over 4m48s) kubelet, 10.168.100.4 Pulling image "10.168.100.144:8021/nvcr.io/nvidia/k8s/cuda@sha256:ed723a1339cddd75eb9f2be2f3476edf497a1b189c10c9bf9eb8da4a16a51a59"
这是因为pod拉取的镜像tag不对所导致,需要手动修改image的tag:
# kubectl get ds -n gpu-operator-resources
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
nvidia-container-toolkit-daemonset 2 2 0 2 0 nvidia.com/gpu.deploy.container-toolkit=true 133m
nvidia-driver-daemonset 2 2 2 2 2 nvidia.com/gpu.deploy.driver=true 135m
# kubectl edit ds nvidia-container-toolkit-daemonset -n gpu-operator-resources
#image: 10.168.100.144:8021/nvcr.io/nvidia/k8s/cuda@sha256:ed723a1339cddd75eb9f2be2f3476edf497a1b189c10c9bf9eb8da4a16a51a59
image: 10.168.100.144:8021/nvcr.io/nvidia/cuda:11.2.1-base-ubi8
刷新pod运行情况,可以看到nvidia-container-toolkit-daemonset及nvidia-device-plugin-daemonset运行正常,而nvidia-device-plugin-validation则Init:CreashLoopBackOff失败:
# kubectl get po -n gpu-operator-resources
NAME READY STATUS RESTARTS AGE
nvidia-container-toolkit-daemonset-27qj8 1/1 Running 0 52s
nvidia-container-toolkit-daemonset-g5ndb 1/1 Running 0 51s
nvidia-device-plugin-daemonset-sqfdc 1/1 Running 0 26s
nvidia-device-plugin-daemonset-wldkd 1/1 Running 0 26s
nvidia-device-plugin-validation 0/1 Init:CrashLoopBackOff 1 9s
nvidia-driver-daemonset-m4xjv 1/1 Running 0 137m
nvidia-driver-daemonset-vkrz5 1/1 Running 5 137m
定位该validation所在的节点名(此例中为10.168.100.3):
# kubectl get po nvidia-device-plugin-validation -n gpu-operator-resources -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nvidia-device-plugin-validation 0/1 Init:CrashLoopBackOff 4 2m55s 172.26.222.10 10.168.100.3 <none> <none>
获取启动失败原因:
# kubectl describe po nvidia-device-plugin-validation -n gpu-operator-resources
......
Warning Failed 56s (x5 over 2m21s) kubelet, 10.168.100.3 Error: failed to start container "device-plugin-validation-init": Error response from daemon: linux runtime spec devices: error gathering device information while adding custom device "/dev/nvidiactl": no such file or directory
登录10.168.100.3节点,获取/dev下驱动程序设备名:
# docker ps | grep nvidia-device-plugin-daemonset | grep -v pause
abbea480fdf2 10.168.100.144:8021/nvcr.io/nvidia/k8s-device-plugin "nvidia-device-plugin" 6 minutes ago Up 6 minutes k8s_nvidia-device-plugin-ctr_nvidia-device-plugin-daemonset-sqfdc_gpu-operator-resources_b9988b02-82a6-4637-a7f0-fdee5a448d60_0
# docker exec -it k8s_nvidia-device-plugin-ctr_nvidia-device-plugin-daemonset-sqfdc_gpu-operator-resources_b9988b02-82a6-4637-a7f0-fdee5a448d60_0 /bin/bash
[root@nvidia-device-plugin-daemonset-sqfdc /]# ls /dev/nvidia* -l -h
crw-rw-rw- 1 root root 195, 254 Apr 19 03:52 /dev/nvidia-modeset
crw-rw-rw- 1 root root 237, 0 Apr 19 06:08 /dev/nvidia-uvm
crw-rw-rw- 1 root root 237, 1 Apr 19 06:08 /dev/nvidia-uvm-tools
crw-rw-rw- 1 root root 195, 0 Apr 19 03:52 /dev/nvidia0
crw-rw-rw- 1 root root 195, 255 Apr 19 03:52 /dev/nvidiactl
[root@nvidia-device-plugin-daemonset-sqfdc /]# exit
在主机级别(10.168.100.3)上手动创建/dev/nvidiactl文件, 依据同样步骤在10.168.100.4上查找到相应的设备驱动号也添加/dev/nvidiactl文件:
[root@gpunode1 ~]# mknod -m 666 /dev/nvidiactl c 195 255
[root@gpunode1 ~]# ls /dev/nvidiactl -l
crw-rw-rw- 1 root root 195, 255 Apr 19 02:19 /dev/nvidiactl
delete掉nvidia-device-plugin-validation这个pod后,kubelet将重新拉起一个,此时报错信息有变化,提示缺少/dev/nvidia-uvm设备驱动文件:
Warning Failed 10s (x2 over 11s) kubelet, 10.168.100.4 Error: failed to start container "device-plugin-validation-init": Error response from daemon: linux runtime spec devices: error gathering device information while adding custom device "/dev/nvidia-uvm": no such file or directory
按照上面创建/dev/nvidiactl的方法创建/dev/nvidia-uvm驱动文件,注意设备号与容器中保持一致:
# mknod -m 666 /dev/nvidia-uvm c 237 0
删除pod后重新拉起,报错信息为缺少/dev/nvidia-uvm-tools:
Warning Failed 9s (x2 over 10s) kubelet, 10.168.100.4 Error: failed to start container "device-plugin-validation-init": Error response from daemon: linux runtime spec devices: error gathering device information while adding custom device "/dev/nvidia-uvm-tools": no such file or directory
手动创建nvidia-uvm-tools设备文件后删除pod等待kubelet重新拉起pod:
# mknod -m 666 /dev/nvidia-uvm-tools c 237 1
Warning Failed 12s (x2 over 12s) kubelet, 10.168.100.3 Error: failed to start container "device-plugin-validation-init": Error response from daemon: linux runtime spec devices: error gathering device information while adding custom device "/dev/nvidia-modeset": no such file or directory
手动创建nvidia-modeset设备文件后删除pod等待kubelet重新拉起pod:
# mknod -m 666 /dev/nvidia-modeset c 195 254
Warning Failed 13s (x2 over 14s) kubelet, 10.168.100.4 Error: failed to start container "device-plugin-validation-init": Error response from daemon: linux runtime spec devices: error gathering device information while adding custom device "/dev/nvidia0": no such file or directory
手动创建nvidia0设备文件后删除pod等待kubelet重新拉起pod:
# mknod -m 666 /dev/nvidia0 c 195 0
# kubectl get po -A | grep device-plugin-validation
gpu-operator-resources nvidia-device-plugin-validation 0/1 Completed 0 2m26s
此时kubelet将继续拉起剩余的nvidia资源,最终状态应该是:
# kubectl get po -A
NAMESPACE NAME READY STATUS RESTARTS AGE
default chart-1618804240-node-feature-discovery-master-5f446799f4-sk7vg 1/1 Running 0 163m
default chart-1618804240-node-feature-discovery-worker-5sllh 1/1 Running 1 163m
default chart-1618804240-node-feature-discovery-worker-86w4w 1/1 Running 0 163m
default chart-1618804240-node-feature-discovery-worker-fl52v 1/1 Running 0 163m
default gpu-operator-945878fff-88thn 1/1 Running 0 163m
gpu-operator-resources gpu-feature-discovery-p6zqs 1/1 Running 0 53s
gpu-operator-resources gpu-feature-discovery-x88v4 1/1 Running 0 53s
gpu-operator-resources nvidia-container-toolkit-daemonset-27qj8 1/1 Running 0 26m
gpu-operator-resources nvidia-container-toolkit-daemonset-g5ndb 1/1 Running 0 26m
gpu-operator-resources nvidia-dcgm-exporter-c9vht 1/1 Running 0 74s
gpu-operator-resources nvidia-dcgm-exporter-mz7rh 1/1 Running 0 74s
gpu-operator-resources nvidia-device-plugin-daemonset-sqfdc 1/1 Running 0 25m
gpu-operator-resources nvidia-device-plugin-daemonset-wldkd 1/1 Running 0 25m
gpu-operator-resources nvidia-device-plugin-validation 0/1 Completed 0 2m47s
gpu-operator-resources nvidia-driver-daemonset-m4xjv 1/1 Running 0 163m
gpu-operator-resources nvidia-driver-daemonset-vkrz5 1/1 Running 5 163m
....
6. 测试GPU
gpu-operator目录下预置了一个test.yaml文件,直接创建:
[root@gpumaster gpu-operator]# kubectl create -f test.yaml
pod/dcgmproftester created
[root@gpumaster gpu-operator]# kubectl get po -o wide | grep dcgmproftester
dcgmproftester 1/1 Running 0 103s 172.26.243.149 10.168.100.4 <none> <none>
找寻到10.168.100.4上的nvidia-device-plugin-daemonset的pod, 观察该节点上gpu的功耗及显存占用情况,可以看到该工作负载确实使用了gpu中的运算单元:
# kubectl exec nvidia-device-plugin-daemonset-wldkd -n gpu-operator-resources nvidia-smi
nvidia 33988608 269 nvidia_modeset,nvidia_uvm, Live 0xffffffffa05dd000 (PO)
Mon Apr 19 06:39:26 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-PCIE... On | 00000000:00:08.0 Off | Off |
| N/A 61C P0 208W / 250W | 493MiB / 32510MiB | 84% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
测试完毕后该pod将处于completed状态,观察其输出:
# kubectl get po -o wide | grep dcgm
dcgmproftester 0/1 Completed 0 4m12s 172.26.243.149 10.168.100.4 <none> <none>
# kubectl logs dcgmproftester
.....
TensorEngineActive: generated ???, dcgm 0.000 (74380.8 gflops)
TensorEngineActive: generated ???, dcgm 0.000 (75398.9 gflops)
TensorEngineActive: generated ???, dcgm 0.000 (75787.6 gflops)
TensorEngineActive: generated ???, dcgm 0.000 (77173.9 gflops)
TensorEngineActive: generated ???, dcgm 0.000 (75669.5 gflops)
Skipping UnwatchFields() since DCGM validation is disabled