
用Superset可视化武汉肺炎数据
Mar 13, 2020
Technology
前言
最近因为武汉肺炎的原因一直宅在家里,刷什么值得买的时候看到了一个玩mac mini server的哥们写的用superset可视化武汉肺炎的文章,照着做了一遍,将具体的步骤都写在了下面。后续做实际项目的BI内容可视化的时候可以用来参考。
该文章中也有少许操作步骤方面的错误,做的时候经常会卡在那里半天。当然如果按照下面记录的步骤来进行的话,这些问题应该不会出现。
环境
涉及到的硬件、操作系统、软件等的情况列举如下:
KVM虚拟机,4核,3G内存, 200G硬盘
Ubuntu18.04.3 x86_64
docker/docker-compose
搭建superset
通过 docker启动superset, 启动后监听 8088 端口:
# sudo docker run -d --name superset -p 8088:8088 amancevice/superset
初始化数据库:
# sudo docker run -d --name superset -p 8088:8088 amancevice/superset
cf39f0c9e6a1232796cfe9012d110d6dd50613a8e2022873c963974eb74c18ba
root@node:/mnt2# docker exec -it superset superset-init
Username [admin]:
User first name [admin]:
User last name [user]:
Email [admin@fab.org]:
Password:
Repeat for confirmation:
现在可以用admin用户及刚才创建的密码登录superset界面了:
登录后界面如下:
准备数据
肺炎的数据从以下页面取得:
https://github.com/canghailan/Wuhan-2019-nCoV
点击下面链接中数据接口里的csv,将csv文件下载到本地:

csv文件可以方便的用libreoffice或者excel打开,后面我们将用libreoffice对数据做一点点更改以支持superset中的地图显示。
手动建立省份代码csv文件( province.csv ), 这个文件是ISO3316标准下的中国省份代码,因为superset的地图中需要使用该标准下的代码:
编码,城市
北京市,CN-11
天津市,CN-12
河北省,CN-13
山西省,CN-14
内蒙古自治区,CN-15
辽宁省,CN-21
吉林省,CN-22
黑龙江省,CN-23
上海市,CN-31
江苏省,CN-32
浙江省,CN-33
安徽省,CN-34
福建省,CN-35
江西省,CN-36
山东省,CN-37
河南省,CN-41
湖北省,CN-42
湖南省,CN-43
广东省,CN-44
广西壮族自治区,CN-45
海南省,CN-46
重庆市,CN-50
四川省,CN-51
贵州省,CN-52
云南省,CN-53
西藏自治区,CN-54
陕西省,CN-61
甘肃省,CN-62
青海省,CN-63
宁夏回族自治区,CN-64
新疆维吾尔自治区,CN-65
在libreoffice中打开两个csv文件后,在Wuhan-2019-nCov 的工作空间里新建一个tab将 province.csv内容全盘复制进来, 并将此tab命名为 province:
接下来我们使用vlookup用来将ISO3316的省份代码插入到Wuhan-2019-nCov表中, 首先在province栏后新建一栏,命名为3316code:
此栏目现在是空的,我们需要用函数将其批量替换为省份对应的代码,如,湖北省 -> CN-41, 首先选中E中的第一个空白栏,而后点击fx按钮,在弹出的函数选择框中输入 vookup 后,启动函数编辑器:
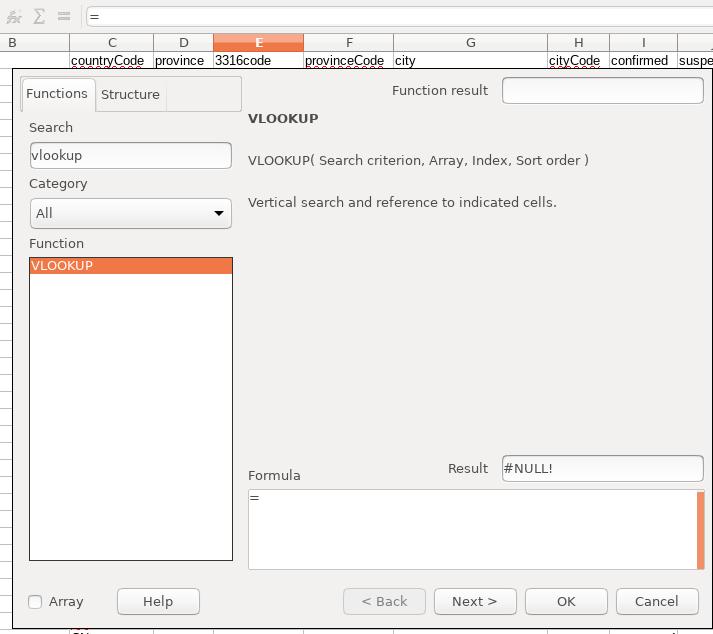
点击 Next 后进入到函数参数输入界面, 首先配置搜索条件, 在Search criterion中填入D:D, libreoffice里将自动选择D全栏, 代表搜索省份中所有的条目:
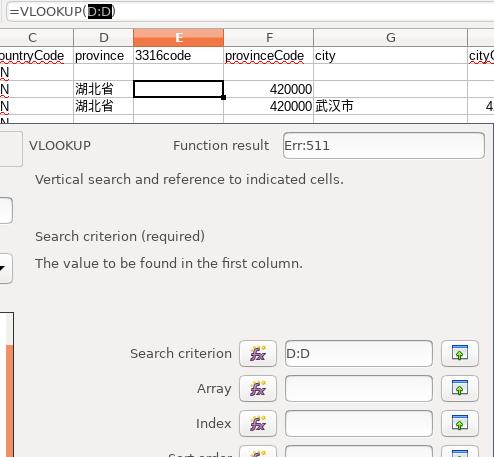
选中Array后,鼠标点击切换到 Province 表, 选中A/B全栏, 或者直接输入 $Province.A:B,匹配:
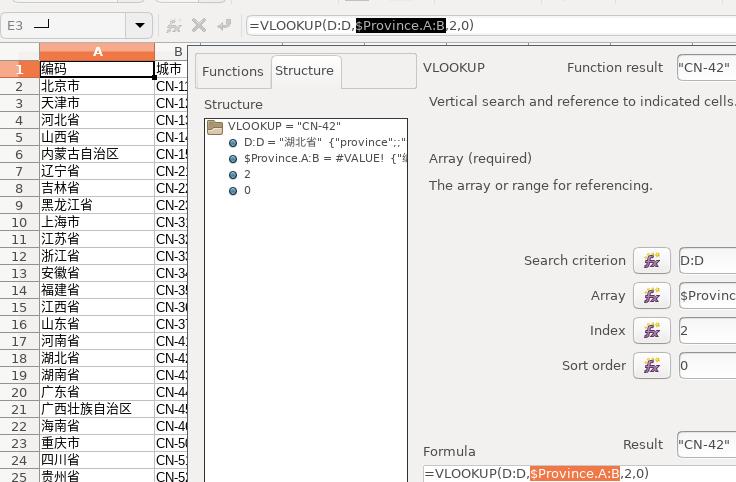
Index 输入数值2, 代表从匹配变量一栏开始需要匹配的数据为第2栏,而 Sort order则输入0后,可以看到输出结果为 CN-42, 代表已经匹配成功:
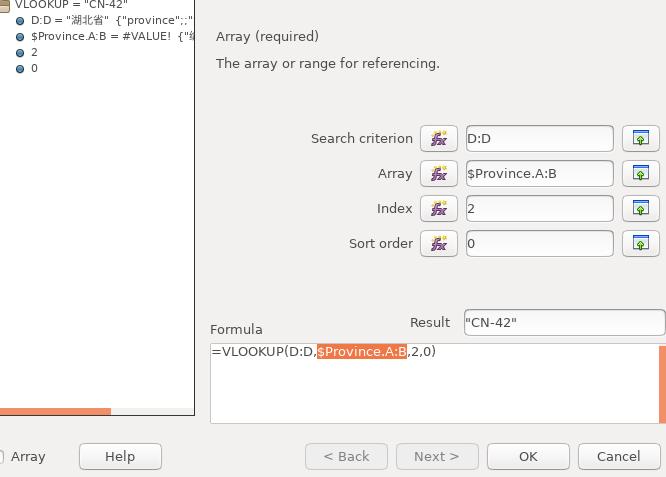
点击 OK 后,点击函数将其扩展到以下几行,观察结果:
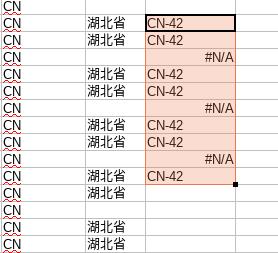
可以看到有 #N/A 的错误输出结果,我们需要修改函数忽略掉此输出:
修改函数为 IFERROR(VLOOKUP(D:D, $Province.A:B,2,0),"")之后,查看结果:
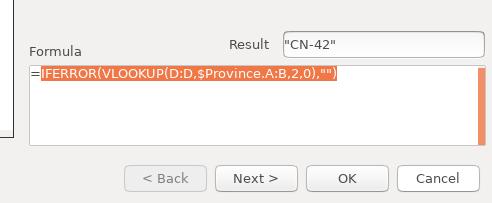
结果显示正常:
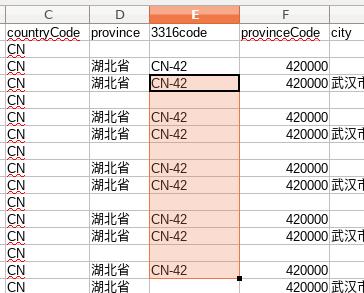
接下来将此函数应用到全列, 选中一个已经应用公式的条目后,如E30, 按住shift键,鼠标一直拉到E的最后一行后,点最后一个元素,选中全列,而后按Ctrl+D,将公式应用到全列,如:
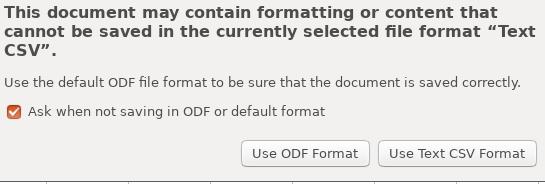
现在保存此csv文件,命名为 nCovForSuperset.csv后退出, 注意要选择 Use Text CSV Format 。
至此,数据准备完毕。
建立数据源
用sqlite3建立一个 假 的数据文件:
# sqlite3 test.db
SQLite version 3.22.0 2018-01-22 18:45:57
Enter ".help" for usage hints.
sqlite> .quit
# ls
nCovForSuperset.csv province.csv test.db Wuhan-2019-nCoV.csv
我们将 此 test.db文件拷贝到容器中, 并通过root用户改变其文件权限:
# docker cp test.db superset:/home/superset/
# docker exec -it --workdir /root --user root superset chmod 777 /home/superset/test.db
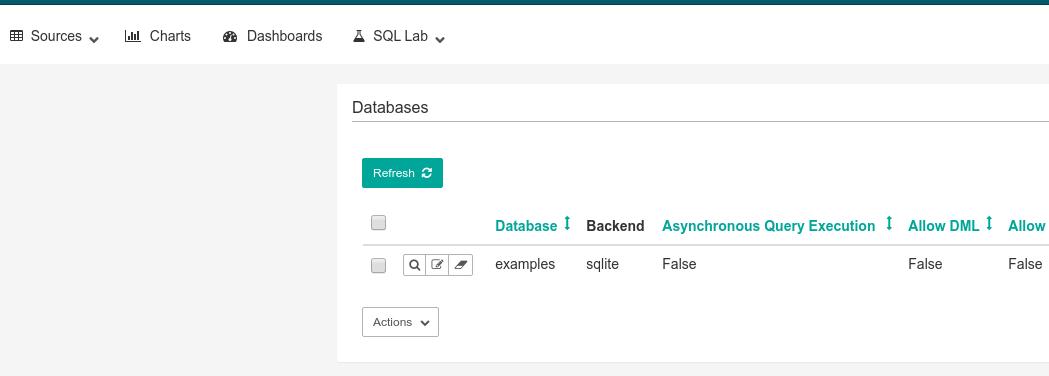
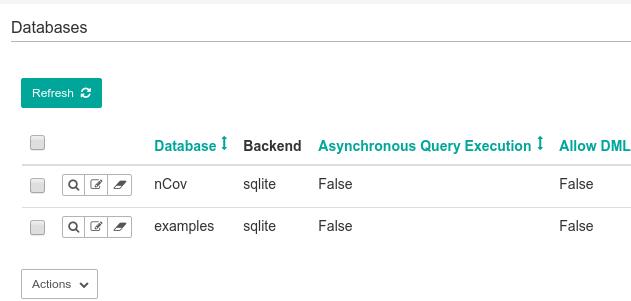
在Superset界面中点击 Sources -> Database, 后,进入到配置数据库的界面:
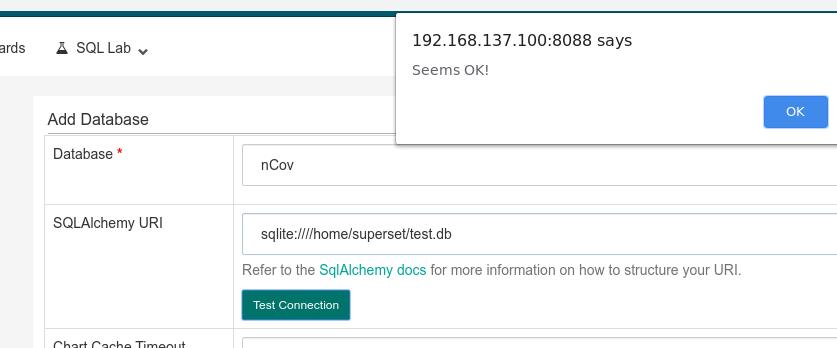
点击 + 号,新加一个数据库, 输入数据库名,及数据库所在的URI,此例子中为 sqlite:////home/superset/test.db:
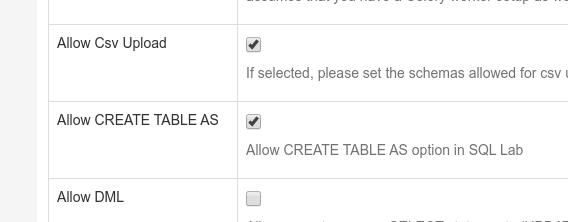
勾选 Allow Csv Upload 及 Allow CREATE TABLE AS:
之后点击 Save, 可以看到数据库已经被建立起来:
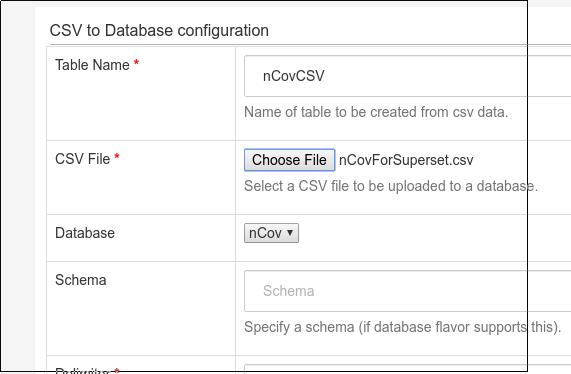
上传刚才编辑好的CSV文件:
会报出出错,提示因权限问题无法上传此CSV文件:
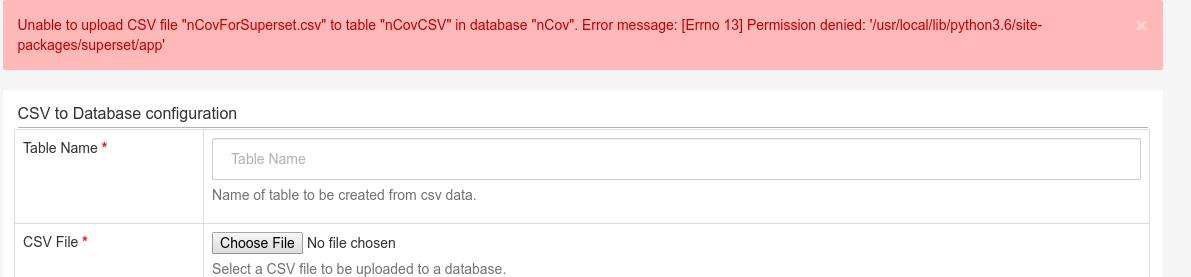
手动建立目录并改变其权限:
# docker exec -it --workdir /root --user root superset mkdir -p /usr/local/lib/python3.6/site-packages/superset/app
# docker exec -it --workdir /root --user root superset chmod 777 -R /usr/local/lib/python3.6/site-packages/superset/app
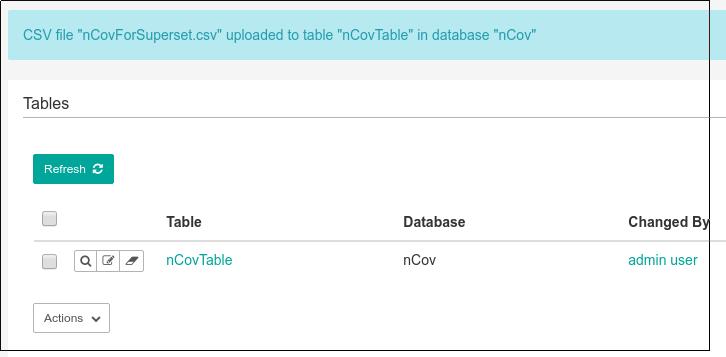
上传成功后可以看到Tables中有了新的文件:
更改tables属性
CSV上传后,大部分的字段(数据) 并没有被确定为准确的类型,superset需要从这些数据中知道哪些是数据,哪些是时间,哪些又可以被归类,为此我们需要编辑此Table中的数据:
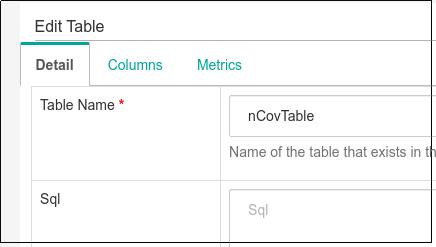
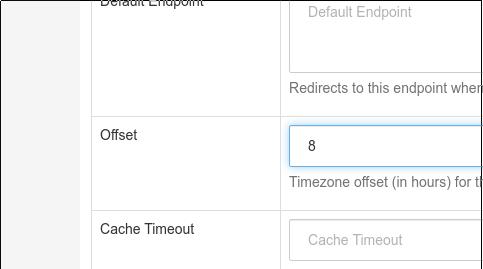
点击Edit Table 进入编辑界面,首先更改Detail中的 Offset为8,代表时区与UTC差别为8:
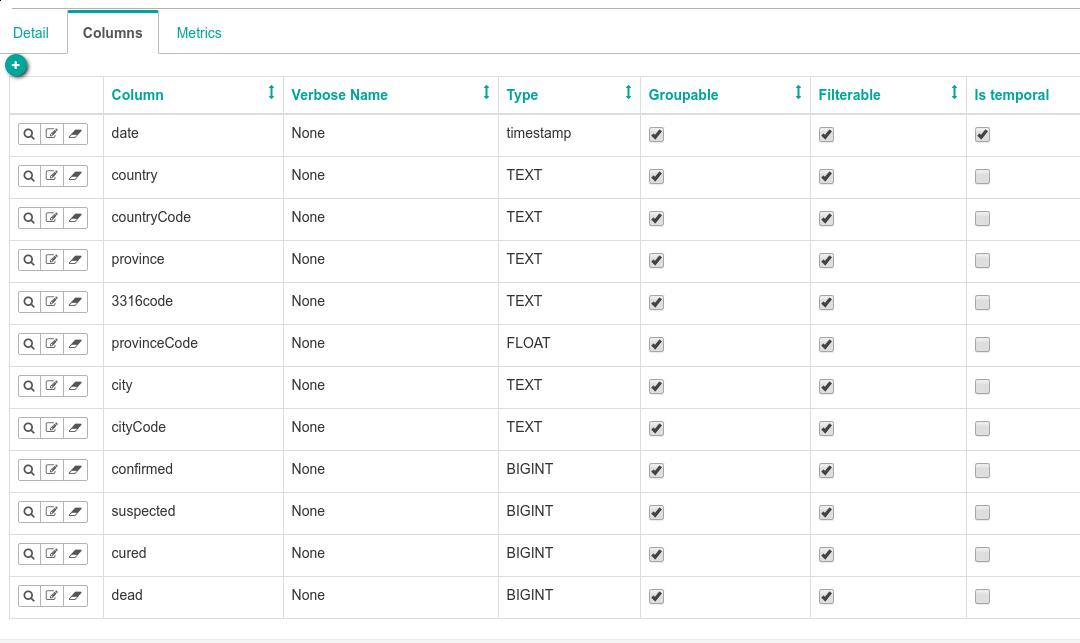
而后开始编辑 Columns, 相关属性说明: groupable 代表是否可以分组; filterable 代表是否可以分类; is temporal 代表是否是时间参数。我们需要把date的type设置为timestamp, 并选取其 is temporal 属性,其他的所有字段的 groupable 及 filterable 都勾上:
Metrics一栏暂时不做任何设置,至此数据已经清晰化,下一步进入数据分析环节.
数据分析
点击 Sources -> Tables ,选中我们刚才上传的CSV文件建立的表后,进入到数据可视化编辑界面,初次进入时界面是完全空白的,我们需要在这里添加相关图表。
中国地图
点击 Visualization Type, 选择 Country Map:
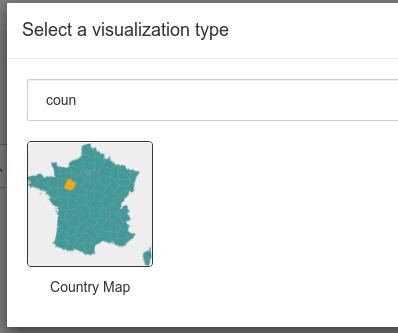
选择为以下值时候,运行 Run Query:
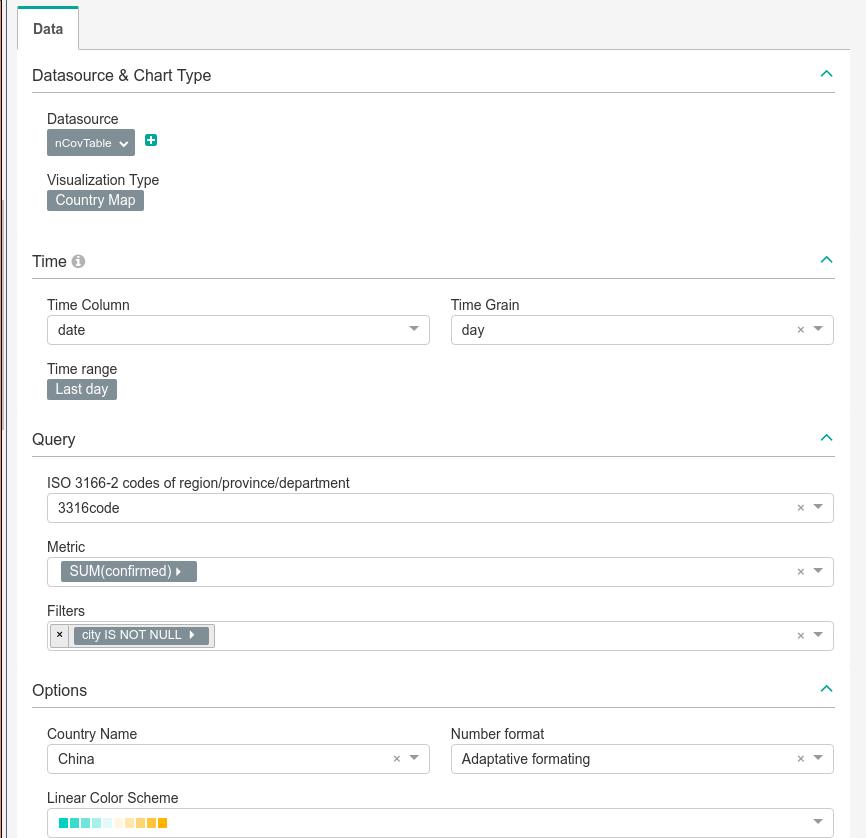
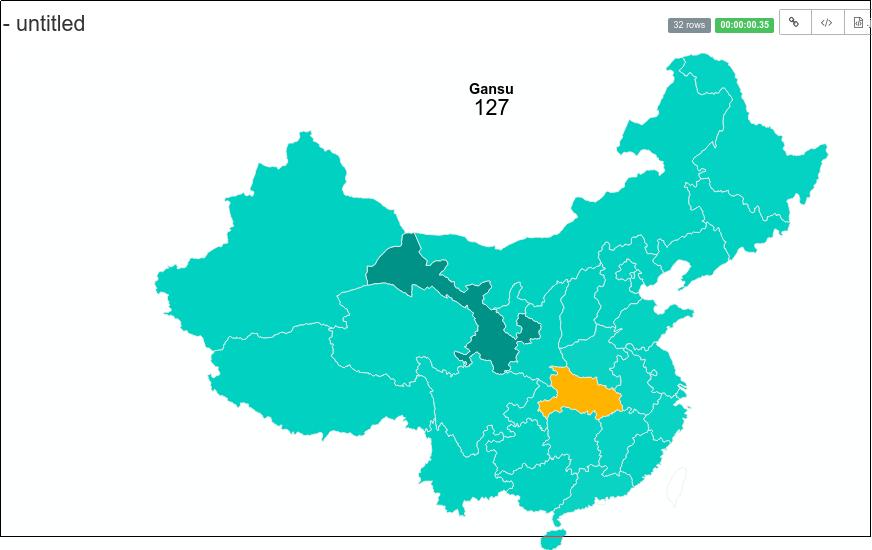
结果如下,比如,选择甘肃,可以看到累计的确诊人数为127人:
编辑完后,点击save即可保存,我们保存为chinamap:
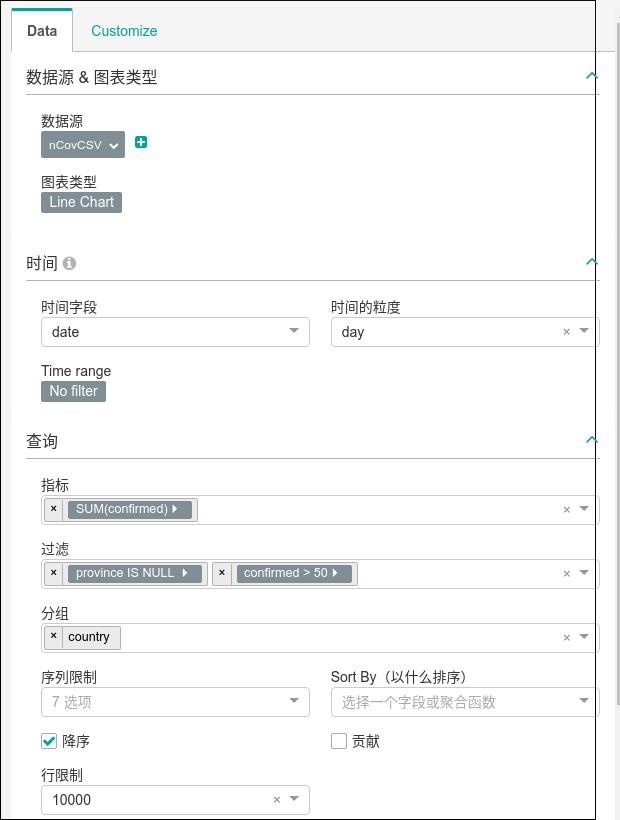
时间线地图
建立一个类型为 Line Charts的图表,数据类型如下:
结果如下:
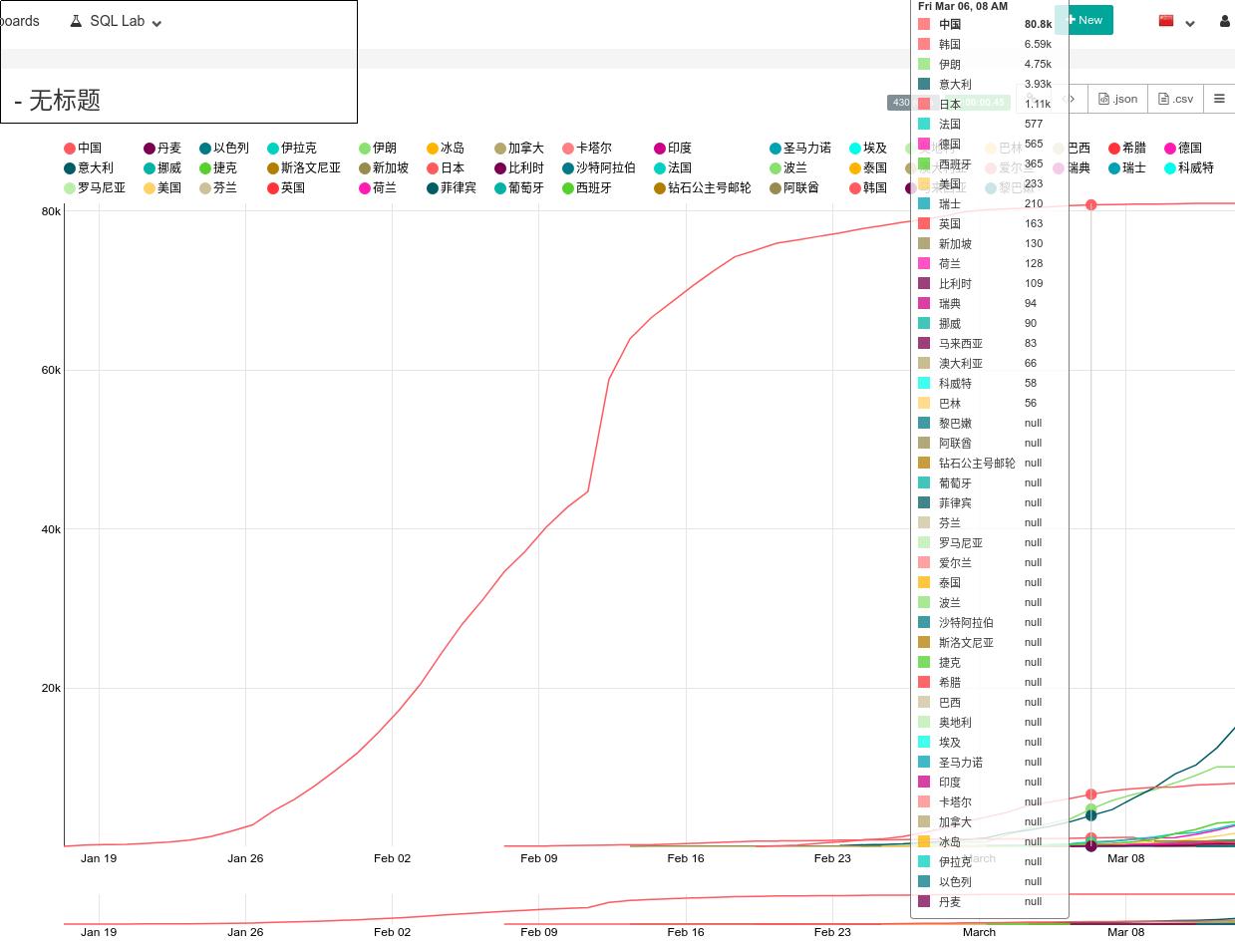
保存名称为 Trend.
sunburst类型
数据类型如下:
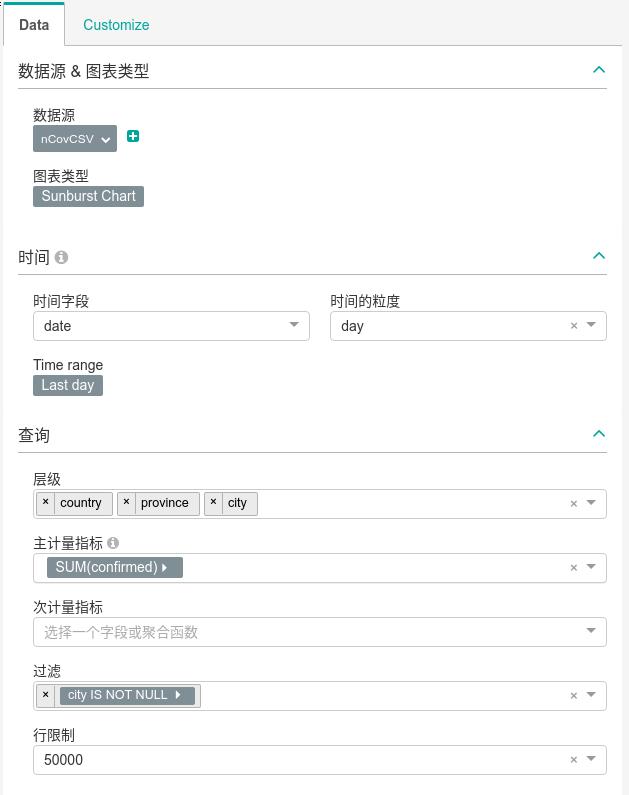
结果:
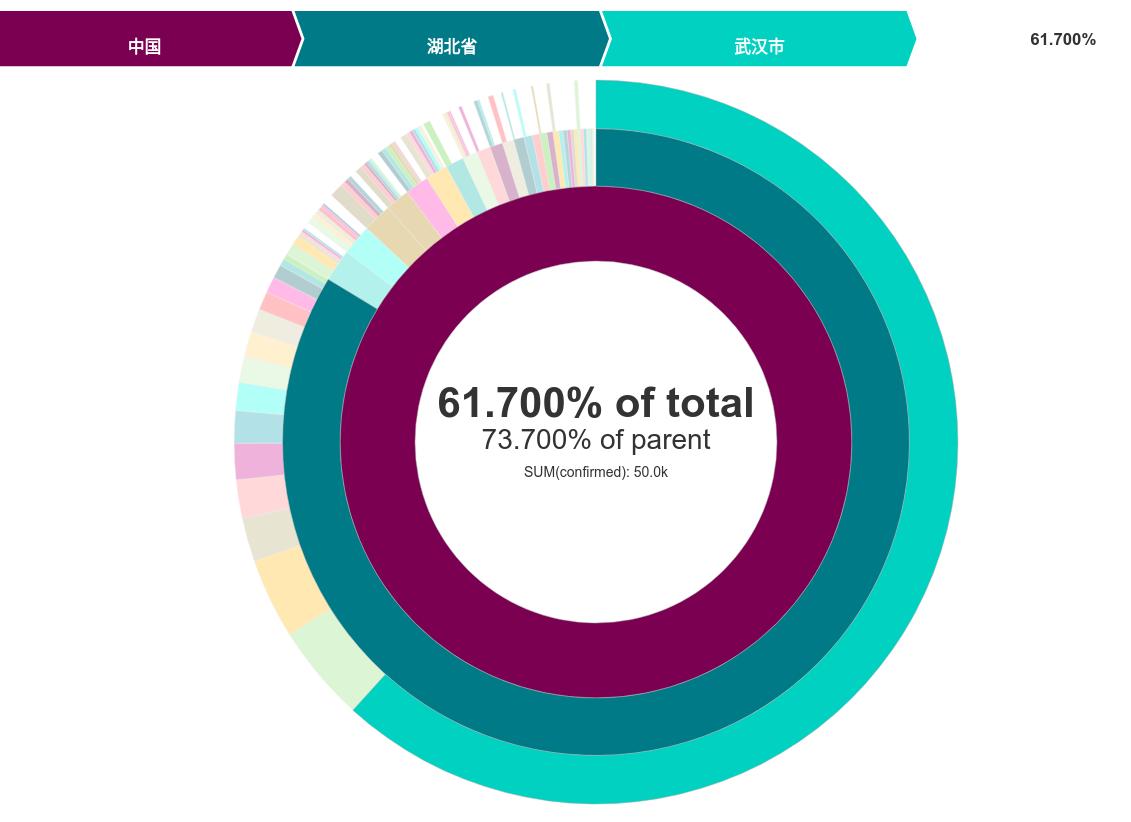
保存名称为 SunburstChina
ForceDirected类型
数据定义如下:
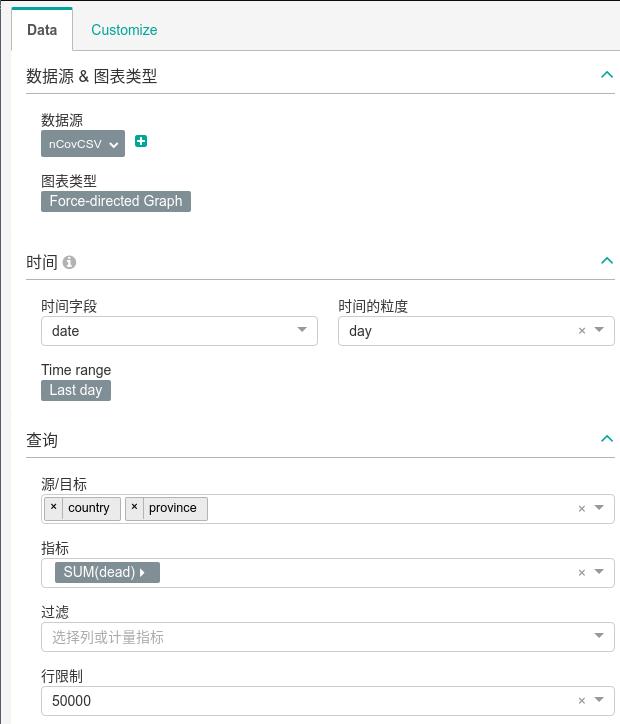
结果:

保存名称为: totalDead.
至此所有的单图表创建完毕.
Dashboard
增加一个Dashboard:
点击Edit,添加对应的图表到该dashboard上即可:
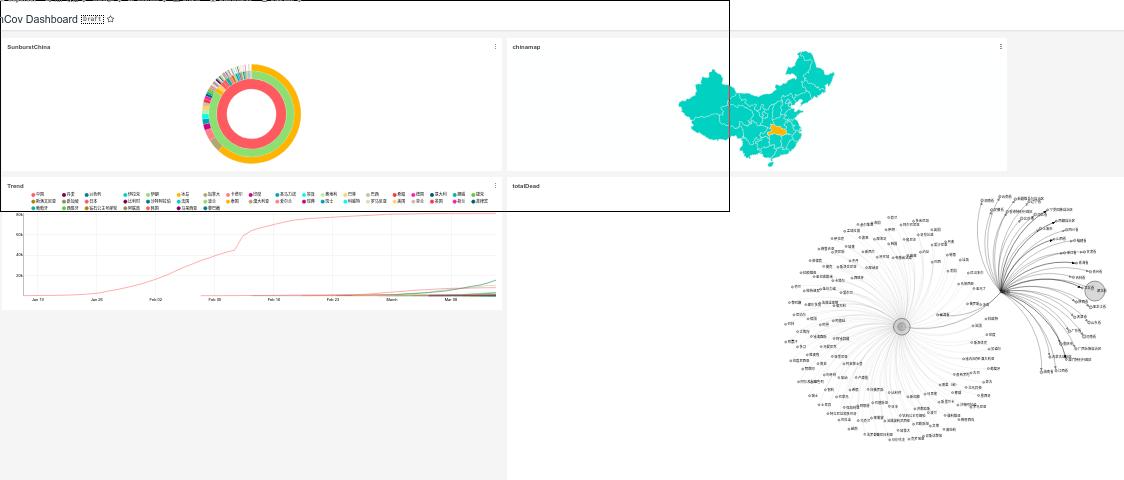
至此,可视化完毕,可以探索更多的样例做出更多的可视化效果。